①如何规避宏观数据建模时可能存在的错误、②如何对宏观数据进行必要的清洗和处理、③如何优化宏观数据的建模质量、以及④宏观数据在投资决策中有哪些应用场景,是投资者在使用宏观数据时必须要考虑的问题。本篇报告针对以上问题进行了探讨,以期让投资者在投资决策中能够能为有效的使用宏观数据。
需要规避的问题指:如果在使用宏观数据时出现了下述情况,则模型具有根本性错误,结论不具有任何可参考意义。
1)滞后性:多数重要宏观指标均会在下月(下季)公布当月(当季)的指标值。若在每月末使用宏观数据的当月值,则会在模型中引入未来数据,使结论无意义。处理宏观数据滞后性有两种方式:定期后移法与动态后移法。
2)数据前修:宏观指标可能会进行初值修订与口径变化,使当前看到的值并非发布时的初始值。实践中需要我们针对每一个宏观指标,去确定其是否存在初值修订或口径变化问题。
3)虚假回归:部分宏观数据与资产走势之间的数理相关性与其经济学逻辑相悖。虚假回归可能带来严重的过拟合现象,使模型结果无意义。虚假回归的问题一个有效的解决方法是预先明确宏观指标与未来资产走势之间的逻辑方向。
需要处理的事项指:如果在使用宏观数据时没有处理以下事项,则宏观数据的质量相对较差,虽不会使模型结果完全无意义,但会影响结果的可信度。
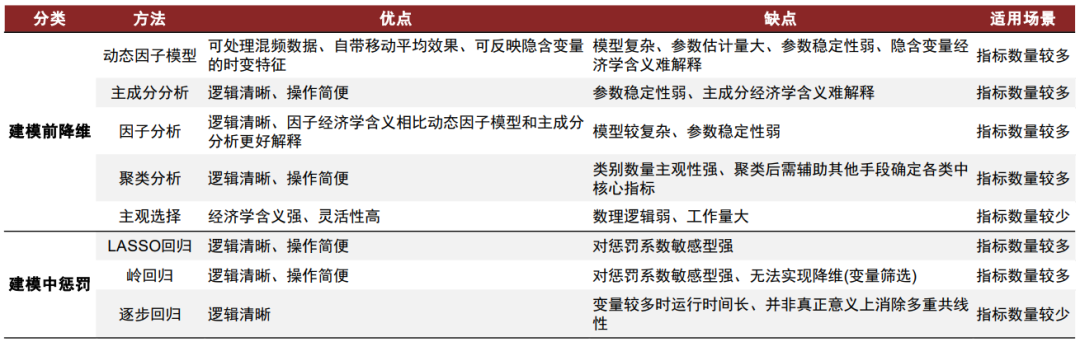
1)指标间相关性:宏观数据数量众多,难免会存在经济逻辑相似或历史取值接近的指标。指标间相关性可能使模型存在多重共线性问题,造成模型结果稳定性下降。处理指标间相关性有两类方式:建模前降维以及建模中惩罚。
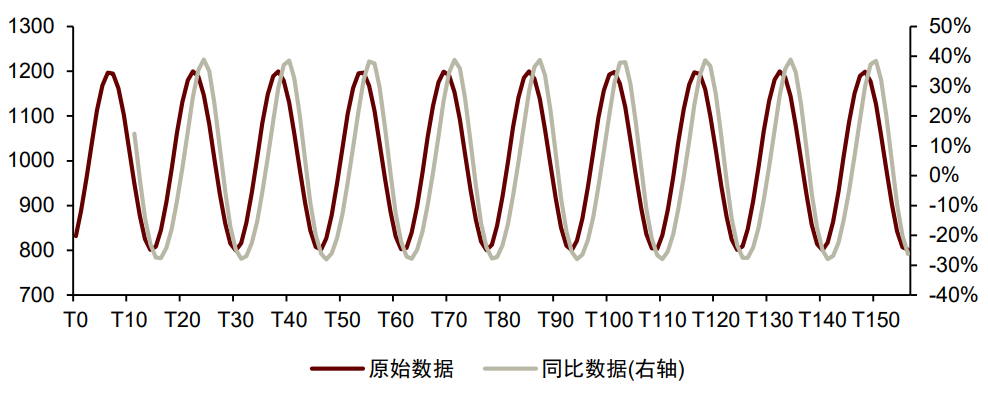
2)季节性:宏观数据可能在不同月份表现出有一定规律的高低变化。季节性可能使宏观数据难以正确反映经济状态的实际变化,造成模型结果有效性的降低。处理宏观数据季节性有两类方式:计算同比以及X-13-ARIMA方法。
3)春节效应:春节假期往往落在1、2月份,从而干扰部分宏观数据在前两个月的取值。春节效应使得部分宏观数据前两个月数据质量降低,进而影响建模效果。处理春节效应有三类方式:合并前两月、变更参照日、季节性调整。
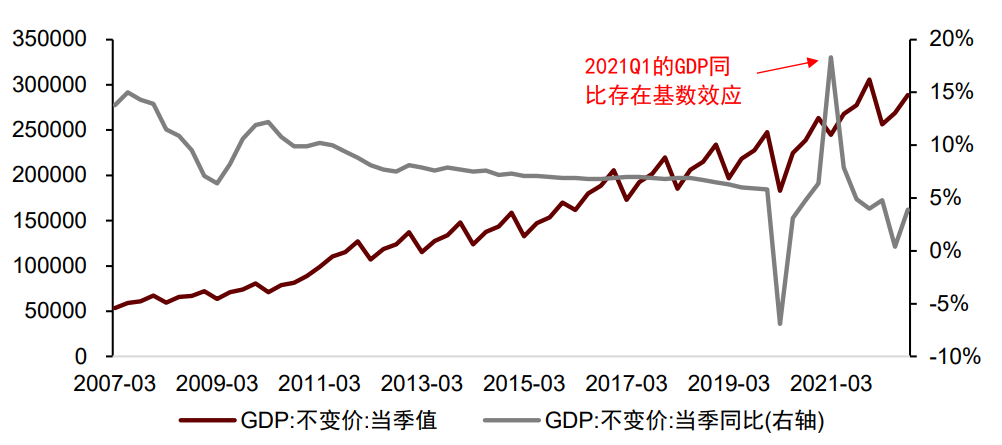
4)基数效应:计算增速时,上一期的异常值会对本期增速有较大的影响。基数效应使同比或环比变化难以反映经济运行真实状态,使模型结果有效性降低。处理基数效应有三类方式:复合增长率、历史值填充、X-13-ARIMA方法。
5)翘尾效应:计算同比时,之前指标的变化会对当前同比产生延伸影响。翘尾效应反映的是“正确数据”下的“延后状态”,如果想要去除翘尾效应,最好的方式是将同比数据转化为环比数据。
可以优化的角度指:如果在使用宏观数据时进行了[文]对应的优化,则对模型具有锦上添花的效果。
1)考虑领先滞后关系。考虑领先滞后关系可以:①通过领先指标对滞后指标进行预测;②在建模时优先纳入领先指标、谨慎使用滞后指标。本文介绍了三种通过数量化方法判断领先滞后关系的方法:线性回归、格兰杰因果关系检验和脉冲响应分析。
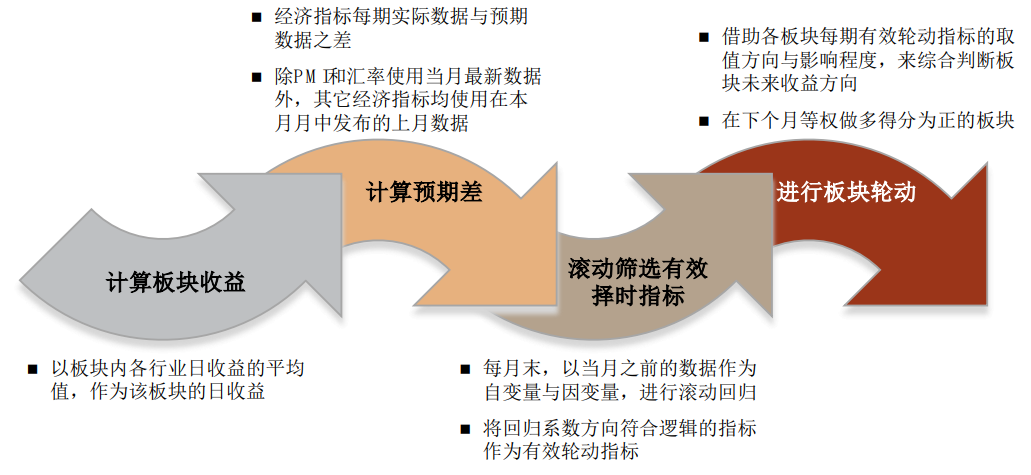
2)引入宏观预期数据。宏观预期数据具有三方面优势:①与实际数据直接可比;②时效性强;③具有瞬时信息增量。我们在之前报告中实证展示了宏观预期数据在资产配置、因子择时、板块轮动中的应用效果。
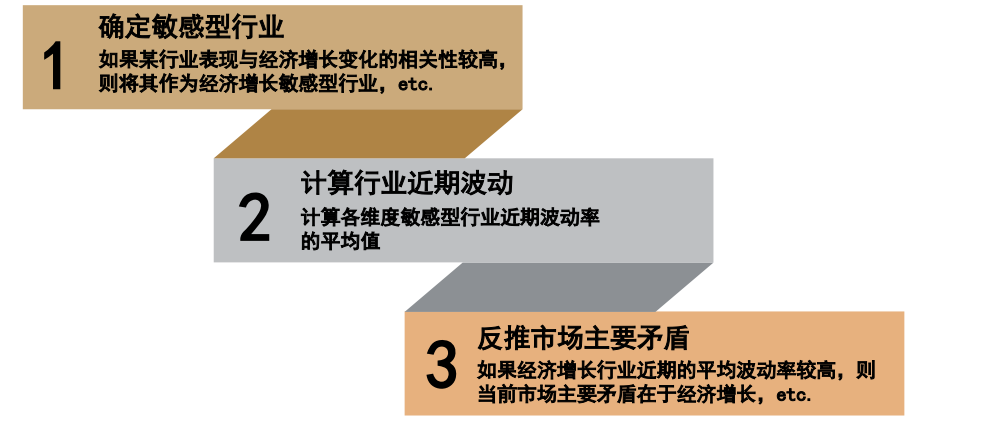
3)判断宏观主要矛盾。经济增长、宏观流动性、通胀等因素,都会在特定情景下成为影响当时股票市场走势的主要宏观矛盾。本文介绍了两种宏观主要矛盾的判断方法:敏感型行业法和文本分析法。
宏观数据在实际投资中有着丰富的应用场景。本文介绍了六个常用的应用场景:Nowcast、资产择时与配置、行业轮动、风格轮动、行业景气度、因子选股,并展示中金量化团队的已有应用实践成果。
风险提示:模型基于历史数据构建,未来存在失效风险。
我们在进行投资决策时,经常会使用到各种宏观数据。如何规避宏观数据建模时可能存在的错误、如何对宏观数据进行必要的清洗和处理、如何优化宏观数据的建模质量、以及宏观数据在投资决策中有哪些应用场景,是投资者在使用宏观数据时必须要考虑的问题。本篇报告将针对以上问题进行探讨,以期让投资者在投资决策中能够能为有效的使用宏观数据。

需要规避的问题指:如果在使用宏观数据时出现了下述情况,则模型具有根本性错误,结论不具有任何可参考意义。我们在本篇报告中指出了3方面需要规避的问题:①宏观数据发布的滞后性;②宏观数据可能存在的前修情况;③宏观数据建模时的虚假回归现象。宏观数据的滞后性体现为:多数重要宏观指标均会在下月(下季)公布当月(当季)的指标值。因此在统计建模时,若在每月末使用宏观数据的当月值,如在10月末使用10月份的CPI数据,则会在模型中引入未来数据,使结论无意义。处理宏观数据滞后性有两种方式:定期后移法与动态后移法。► 定期后移法是指根据宏观数据的公布频率,在下一期末使用上一期的数据,如月频公布的指标在下月末应用上月的数据,季频公布的指标在下季末应用上季的数据。定期后移法的应用前提是宏观数据确定会在下一期末之前公布当期数据,若存在滞后期过长的宏观数据(如美国能源信息署提供的各大洲原油产量数据),或因特殊原因延迟公布的数据(如工业增加值在3月份分别公布1、2月的环比数据),则定期后移法处理后仍可能会引入未来数据,此时需要更长期限的后移才能消除宏观数据的滞后性。► 动态后移法是指回溯宏观数据的历次发布日期来进行对应后置。动态后移法可以对宏观指标的每一期进行精准后置,适用于精细建模使用。相对来说,定期后移法的优点在于操作简便,用到未来数据的概率较低,缺点在于数据时效性差;动态后移法的优点在于数据时效性强,缺点在于需要对每个指标确定其每一期后置窗口,工作量较大。在实际应用中,我们建议对于重要与常用的宏观指标使用动态后移法,对于相对次要的宏观指标使用定期后移法。我们整理了若干重要宏观指标2010年以来的历次发布时间,供投资者参考。宏观数据的前修体现为两个方面:初值修订与口径变化。► 初值修订是指部分宏观数据会先公布初值,一段时间之后再次发布数据的修订值。如GDP会在每季度公布初步核算数,并在年末或下一年对初步核算数进行修订,以2021年为例,2021全年GDP初步核算数为1143670亿元,而2022年末国家统计局修订2021年全年GDP为1149237亿元,比初步核算数增加了5567亿元,修订造成的结果为初步核算数所计算2021年GDP累计同比为8.1%,而修订后2021年GDP累计同比为8.4%,提高了0.3个百分点。初值修订的风险在于历史回溯时,若在初值发布日使用了修正值,如在2022年1季度使用了修订后的2021年GDP,则会引入未来数据问题,造成模型结果无意义。► 口径变化是指宏观数据的计算方式发生变化,使历史数据出现对应的调整。如社会融资规模在2018年和2019年出现了统计口径的变化,并将2017年以来的历史数据进行了对应调整,从而使得目前看到的2017年的数据并非2017年当时实际公布的数据,即引入了未来数据问题,使模型结果无意义。对于数据前修问题,并没有特别简便通行的处理方法,实践中需要我们针对每一个宏观指标,去确定其是否存在初值修订或口径变化问题。如果宏观指标存在初值修订,则使用该指标时需要精细化时间线,在初值发布后使用初值,修正值发布后使用修正值。如果宏观指标存在口径变化,最为审慎的做法是在口径变化后才使用新口径数据,在口径变化前仍使用旧口径数据,即忽略口径变化对历史数据的调整。我们整理了常用宏观指标的数据前修情况,以及初值和修订值的发布时间和对应的Wind指标名称,供投资者参考。宏观数据的虚假回归体现为:由于样本点较少或传导关系较弱等原因,部分宏观数据与资产走势之间的数理相关性与其经济学逻辑相悖。此时若按照数理相关性去应用宏观数据,则会造成严重的过拟合现象与样本内问题,使模型结果无意义。举例来说,社零月同比是反映我国消费情况最为常用的指标之一,经济学逻辑上应与股市未来表现正相关,但从数理相关性来看,该指标与沪深300下月涨跌方向在2015年之前呈负相关,在2015年之后呈正相关。因此在2015年初的时点,若不考虑社零月同比的经济学逻辑,只按照数理相关性来使用该指标,则会错误的将该指标用成反向指标,造成模型失效。对于虚假回归的问题,一个有效的解决方法是预先明确宏观指标与未来资产走势之间的逻辑方向。若回归系数方向或数理相关性与宏观指标的经济逻辑方向相反,则认为该指标存在过拟合风险,在最终模型中去除该指标或采取其他消除过拟合的行为。我们整理了常用宏观指标对各类资产未来走势的经济学逻辑方向,供投资者参考。图表3:不同宏观指标对资产未来走势的经济学逻辑方向存在差异
需要处理的事项指:如果在使用宏观数据时没有处理以下事项,则宏观数据的质量相对较差,虽不会使模型结果完全无意义,但会影响结果的可信度。我们在本篇报告中指出了5方面需要处理的事项:①指标间相关性;②季节性;③春节效应;④基数效应;⑤翘尾效应。
指标间相关性体现为:宏观数据数量众多,难免会存在经济逻辑相似或历史取值接近的指标。若在模型中引入过多经济逻辑相似相似的指标,则会“超配”对应的经济维度,造成模型有效性下降;若在模型中引入过多历史取值接近的指标,则会使模型存在多重共线性问题,使模型结果稳定性与显著性下降。处理指标间相关性有两类方式:建模前降维以及建模中惩罚。
► 建模前降维是指在宏观数据纳入模型之前,把相关性较高的指标进行“合并”以实现降维,从而将数量众多且相关性较高的原始指标变为数量较少且相关性较低的合成指标,是一个无监督的过程。宏观数据常用的降维方法包括动态因子模型、主成分分析、因子分析、聚类分析等。当然,实际建模中也可根据自身的经济学理解,选择相关性较高的一组指标中,经济学含义更充分的几个来实现降维。► 建模中惩罚是指在应用宏观数据进行预测时,对相关性较高且解释力度较低的指标进行“惩罚”以实现降维,是一个有监督的过程。建模中惩罚一般通过在预测模型的目标函数中设置惩罚项来实现,如LASSO回归、岭回归等;也可以通过逐步回归法间接实现高相关性指标的剔除。宏观数据的季节性体现为:宏观数据受到天气季节变化、节假日分布、生产习俗与周期等因素的影响,在一年的不同月份表现出有一定规律的高低变化。若未去除宏观数据的季节性,则会使宏观数据难以正确反映经济状态的实际变化,造成模型结果有效性的降低。处理宏观数据季节性有两类方式:计算同比以及X-13-ARIMA方法。
► 计算同比是处理季节性相对简便的做法,由于同比变化是当期值相对去年同期值的变化率,因此自然而然去除掉了宏观数据的季节性。但计算同比也有其自身缺陷:①同比数据对趋势变化的反映存在滞后性,其所反映的拐点一般比真实拐点滞后3~6个月左右;②同比数据在消除季节性的同时,可能会引入基数效应、翘尾效应等其他问题。► X-13-ARIMA是由美国人口调查局提出的季节调整方法,全流程分成3个阶段:ARIMA建模、季节调整和诊断。ARIMA建模在季节调整之前,提供前向预测、后向预测和各种效应的先验调整;季节调整是整个流程的核心部分,按照乘法模型或加法模型将调整后的时间序列拆分为趋势—循环(C)、季节(S)和不规则(I)三种成分,并通过一系列步骤得到C、S、I的估计值;诊断部分用于检验所选择的ARIMA模型和季节调整的有效性,包括历史修正、平移/滚动检验、谱分析、MI-M11、Q统计量等。在Python中使用X-13-ARIMA方法可通过statsmodels模块中的x13_arima_analysis程序实现,但其缺陷在于程序仅内置了对西方节假日的调整,未包含中国的春节。我们在x13_arima_analysis程序的基础上增加了对中国春节的调整,使其更适合中国宏观指标应用,供投资者参考。宏观数据的春节效应体现为:春节假期往往落在1、2月份,从而干扰部分宏观数据在前两个月的取值。春节效应使得部分宏观数据每年前两个月的数据质量降低,进而影响建模效果。处理春节效应有三类方式:合并前两月、变更参照日、季节性调整。► 合并前两月是指在将1、2月份的数据合并为前两月的数据。目前许多重要宏观数据,如固定资产投资、社零、工业企业经济效益等,均使用合并前两月的方法处理春节效应。值得注意的是,合并前两月方法不直接适用于同比、环比等增速类数据,需将该类数据还原为初值,再重新计算前两月的同比增速。► 变更参照日是指将春节作为参照日(T=0),计算不同年份的宏观数据在春节前30个日历日的取值之和以及春节后30个日历日的取值之和,分别作为当年1月和2月的数据,再求同比以去除春节效应。这种方法要求宏观数据必须为高频数据,比如日频或周频数据,同时为可累加的数据(非增速类数据)。► 季节性调整是指按照上一小节中介绍的季节性调整方法,对1、2月份的数据去除季节性,从而规避春节效应。若使用计算同比的方式去除季节性,则数据最好为季频数据,因为春节可能在当年落在1月而在上一年落在2月,此时月频数据求同比无法完全去除春节效应。
宏观数据的基数效应体现为:计算增速时,上一期的异常值会对本期增速有较大的影响。基数效应使得同比或环比变化难以反映真正的经济运行状态,使模型结果有效性降低。基数效应较为典型的例子是2021年1季度的GDP,受疫情冲击,2020年1季度GDP处于较低状态,从而使得2021年1季度经济处于正常状态下,计算出的GDP同比增速处于历史最高水平。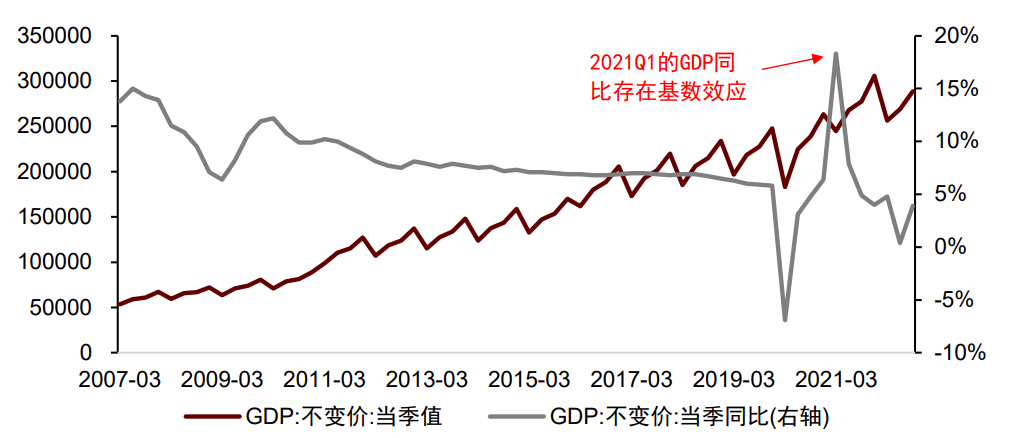
处理基数效应有三类方式:复合增长率、历史值填充、X-13-ARIMA方法。► 复合增长率是指将存在基数效应的数据计算n年复合增长率,从而使“基数”消失。如2021年2月的工业增加值同比因基数效应高达52.34%,则我们可以计算其2年复合增长率,具体来说,2020年2月工业增加值同比为-25.87%,则2021年2月工业增加值的2年复合增长率为[(1-25.87%)*(1+52.34%)]^0.5-1=6.27%,消除了因2020年2月基数过低所带来的基数效应。复合增长率的优势在于操作简便,参数依赖少,可能存在的问题一是钝化了宏观数据的短期变化,二是若n年前数据也是异常值(如假设上例中2019年工业增加值也偏低),则仍会存在基数效应问题。► 历史值填充是指用宏观数据的历史平均值替代上期异常值,从而一定程度消除基数效应。仍以工业增加值为例,由于2020年2月的工业增加值同比过低,我们用2010~2019共10年的2月份工业增加值同比的平均值对其进行替代,数值为8.01%。记修正后2021年2月的工业增加值同比为x,则有(1+8.01%)*(1+x) =(1-25.87%)*(1+52.34%),解得x=4.55%。历史值填充的优势在于操作简便,可能存在的问题一是钝化了宏观数据的短期变化,二是历史平均值随计算时间窗口的不同可能有较大差异。► X-13-ARIMA方法是指通过X-13模型识别出不规则项并将其去除,从而对基数进行调整以消除基数效应。仍以工业增加值为例,为消除2021年2月的工业增加值的基数效应,我们以2010年1月~2021年1月的工业增加值同比序列作为样本,输入X-13模型,模型求得2020年2月的不规则项为-29.41%,即2020年2月工业增加值同比修正值为-25.87%+29.41%=3.54%,记修正后2021年2月的工业增加值同比为x,则有(1+3.54%)*(1+x) =(1-25.87%)*(1+52.34%),解得x=9.07%。X-13-ARIMA方法的优势在于数理逻辑充分,可能存在的问题主要是参数敏感型强,结果随计算时间窗口的不同可能有较大差异。
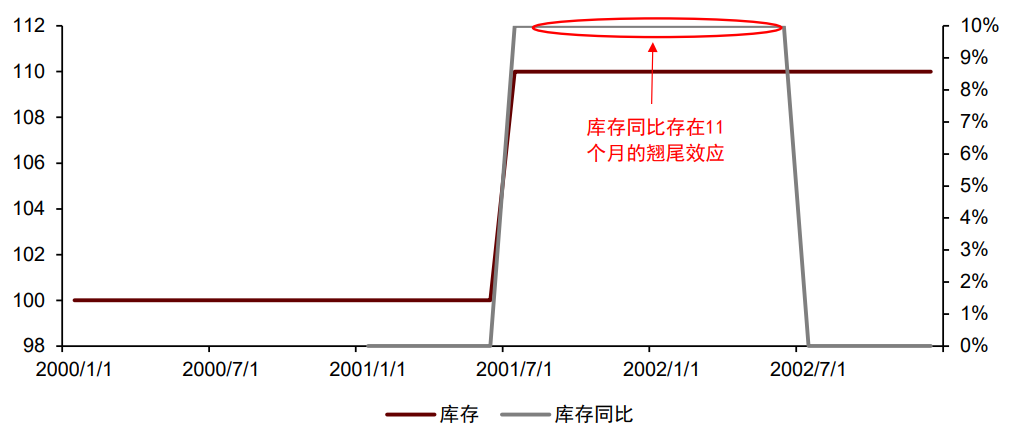
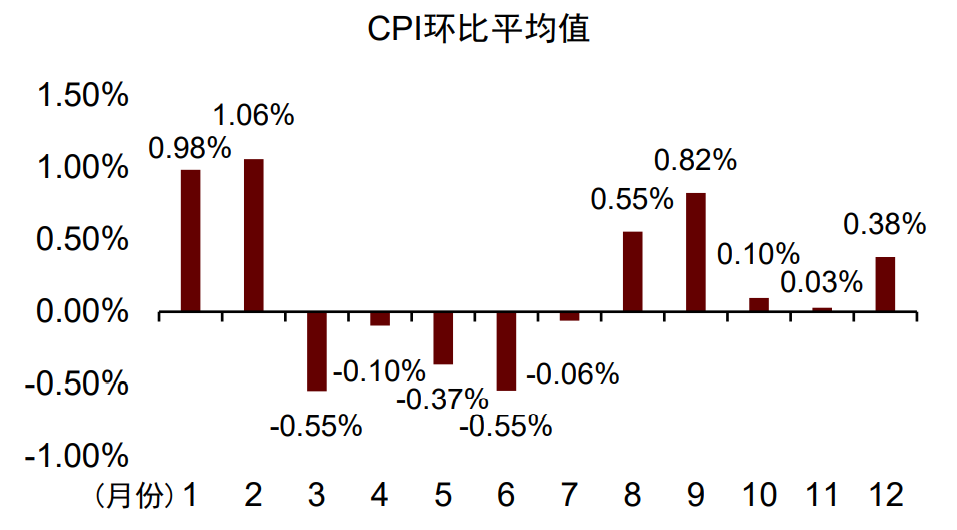
宏观数据的翘尾效应体现为:计算同比时,之前指标的变化会对当前同比产生延伸影响。翘尾效应在存量或状态类指标(如存货或物价)的同比数据中体现尤为明显。以存货为例,假设第1年至第2年前6月存货为100,7月存货增加至110,8~12月存货维持110,第3年存货维持110,则第2年前6月存货同比为0,后6月存货同比为10%,第三年前6月存货同比为10%,后6月存货同比为0。可以看到,存货的增加仅发生在第2年7月,但其对存货同比的影响一直延续至第3年6月,存在11个月的翘尾效应。图表11:存量或状态类指标的同比数据易出现翘尾效应
可通过求环比的方式一定程度消除翘尾效应。翘尾效应反映的是“正确数据”下的“延后状态”,如果想要去除翘尾效应,最好的方式是将同比数据转化为环比数据。以CPI为例,CPI同比序列的一阶自相关系数为98.64%,而CPI环比序列的一阶自相关系数仅为34.00%,间接说明CPI环比的当前值受历史值的影响更小,即翘尾效应更弱。但环比序列可能存在季节性问题,从历史取值看,受春节消费需求影响,1月和2月的CPI环比均值明显高于其他月份,因此通过环比的方式消除翘尾效应时,需要考虑环比序列的季节性问题。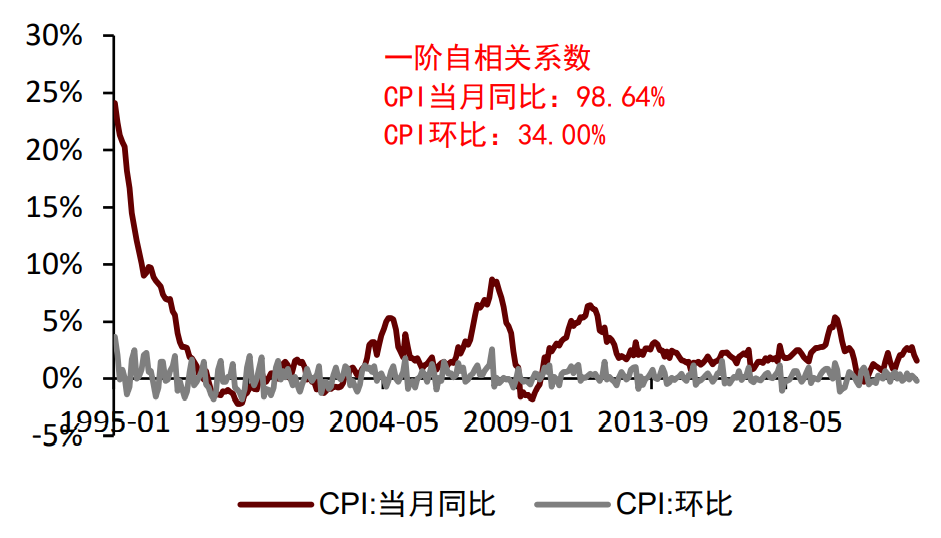
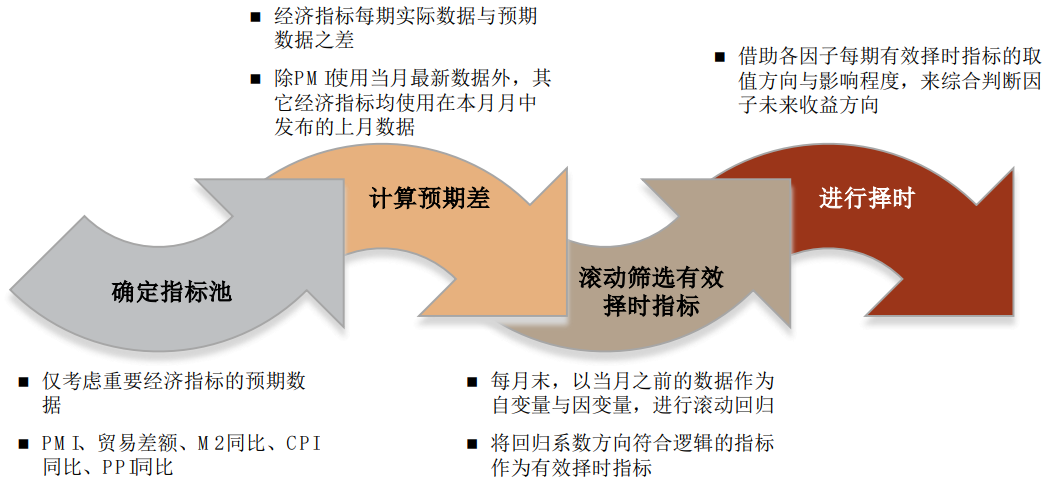
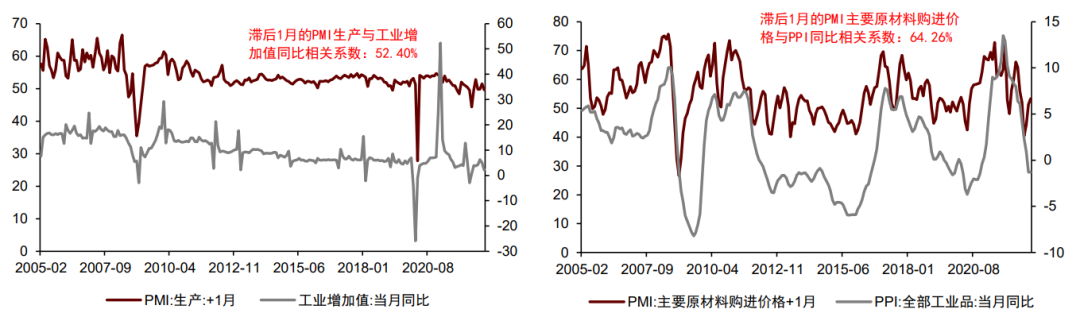
可以优化的角度指:如果在使用宏观数据时进行了对应的优化,则对模型具有锦上添花的效果。我们在本篇报告中列举了3个可以优化的角度:①考虑宏观数据间的领先滞后关系;②建模时引入宏观预期数据;③判断当前宏观维度的主要矛盾。宏观数据的领先滞后关系体现为:某些宏观数据的变化会领先于另一些宏观数据的变化。造成领先滞后关系的原因可分为三类:①同频数据不同发布时点;②同维数据不同发布频率;经济逻辑在多维间传导。► 同频数据不同发布时点指:不同宏观数据在每月的公布时点存在差异,对于经济逻辑接近的同频指标,先发布的指标领先于后发布的指标。比较典型的例子是PMI对各宏观指标的先导性,PMI分项包括生产、新出口订单、进口、主要原材料购进价格等等,其与下月工业增加值同比、出口金额同比、进口同比、PPI同比的相关系数分别可达52.40%、43.50%、52.13%、64.26%,具有较高的正相关性,而PMI的发布时点显著早于其他宏观数据的发布时点,从而带来PMI对其他宏观数据的领先滞后关系。► 同维数据不同发布频率指:一些经济逻辑接近的指标公布频率存在差异,则高频指标对于低频指标具有一定领先性。比较典型的例子是亚特兰大联储GDPNow模型,使用20余个月频数据实时预测季频公布的GDP,从而实现对GDP的领先性估计。► 经济逻辑在多维间传导指:政策的传导和周期的演变在不同经济维度之间存在时间先后关系,进而带来不同宏观数据的领先滞后关系。举例来说,我国经济存在明显的逆周期调节性和投资拉动性,因此金融指标的拐点往往领先于经济指标的拐点(邓创,2014;马勇,2016)。
考虑宏观数据的领先滞后关系对于建模有两方面帮助:①可以通过领先指标对滞后指标进行预测;②可以在建模时优先纳入领先指标,谨慎使用滞后指标。但宏观数据数量庞大,难以通过主观分析的方式判断所有指标之间的领先滞后关系。本篇报告介绍三种通过数量化方法判断领先滞后关系的方法:线性回归、格兰杰因果关系检验和脉冲响应分析。
我们以PMI生产和工业增加值为例,来展示以上三种方法的具体应用流程和效果。由于PMI生产每月末公布当月值,工业增加值每月中公布上月值,因此在时序上我们将当月PMI生产与上月工业增加值对齐,即认为6月的PMI生产和5月的工业增加值是同期数据。
► 线性回归。线性回归是判断领先滞后关系最为简便的方式,以指标Y作为因变量,指标X的滞后项作为自变量,进行一元线性回归。如果回归系数显著,则认为X是Y的领先指标。拓展1:X可设置不同的滞后期,以检验不同时间长度的领先性,但这种做法容易带来较高的过拟合风险,建议只在具有明确经济学传导逻辑的指标间使用,不建议在海量指标间数据挖掘式的使用。拓展2:自变量中可加入Y的滞后项,从而将Y的序列相关性考虑在内。应用实例中,我们以当期工业增加值同比作为因变量,以上期PMI生产和上期工业增加值同比作为自变量,进行线性回归,可得上期PMI生产的回归系数为0.083,P值小于0.01,具有显著正向影响,即PMI生产对工业增加值具有显著领先性。反之,如果以当期PMI生产作为因变量,以当期工业增加值同比和上期PMI生产作为自变量,进行线性回归,可得当期工业增加值同比的回归系数为-0.10,P值大于0.1,经济学和统计学上有效性均较差,即工业增加值对下月PMI生产并不具有领先性。
► 格兰杰因果关系检验。格兰杰因果关系检验的实质是判断加入指标X的滞后性后,对指标Y建模的解释程度能否提高,原假设为X非Y的格兰杰原因,如果检验P值小于临界值,则拒绝原假设,认为X是Y的格兰杰原因。应用实例中,我们检测PMI生产是否为工业增加值的格兰杰原因,结果显示格兰杰因果关系检验的各项P值均小于0.01,即PMI生产对工业增加值具有显著领先性。反之,如果检测工业增加值是否为下期PMI生产的格兰杰原因,则各项P值均大于0.3,即工业增加值对下月PMI生产并不具有领先性。
► 脉冲响应分析。脉冲响应分析是VAR模型中的概念,指的是某个变量受到外生冲击时,其他变量会受到的动态影响。应用在宏观数据的领先滞后关系中,我们可以分析指标X受到外生冲击时,对指标Y下一期取值的动态影响,如果置信区间不包括0(0代表无脉冲),则可以认为X是Y的领先指标。应用实例中,我们检测PMI生产作为脉冲、工业增加值作为响应的结果,其置信区间均大于0,即PMI生产对工业增加值具有显著领先性。反之,如果检测工业增加值作为脉冲、下期PMI生产作为响应的结果,则置信区间包括0,即工业增加值对下月PMI生产并不具有领先性。

一方面,宏观数据的实际值存在我们前文所分析的滞后性、季节性、基数效应等问题,需要进行相对复杂的处理才能在量化建模中有效应用;另一方面,资产价格体现的是对未来的预期,其变化往往领先于宏观数据的发布,因此只关注宏观数据的实际值会造成无法捕捉投资者预期的变化。
出于这两方面原因,投资者可以尝试在建模时引入宏观预期数据。宏观预期数据具有以下几方面优势:► 与实际数据直接可比。分析师在对宏观数据进行预测时,会将宏观数据的季节性、基数效应、翘尾效应等考虑在内,因此宏观数据的预期值和实际值具有较高的可比性,将两者做差得到的超预期数据无需再考虑季节性、基数效应等因素,建模应用难度降低。► 时效性强。资产价格体现的是对未来的预期,其变化往往领先于宏观数据的发布,因此观测宏观预期的动态变化可以及时对资产择时观点进行调整,相比宏观数据公布的实际值来说,具有更高的时效性。► 具有瞬时信息增量。如果我们在经济数据公布前拥有其预期数据,则当实际值公布时,其超预期情况可以产生较大的瞬时信息增量,对于资产短期走势具有较强的指导意义。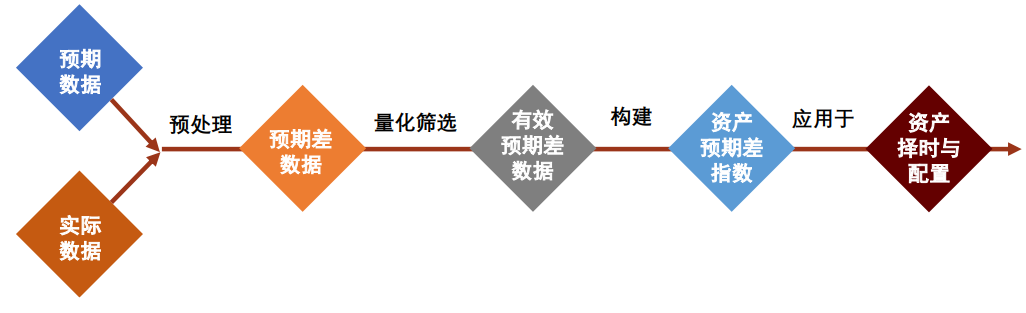
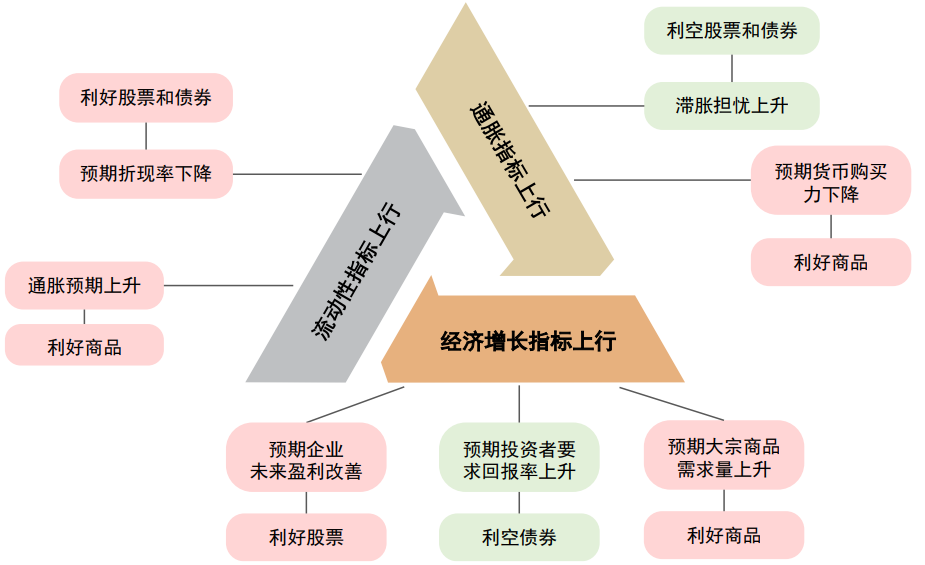
股票市场是多维度信息共同影响的复杂系统。经济增长、宏观流动性、通胀等因素,都会在特定情景下成为影响当时股票市场走势的主要宏观矛盾。主要矛盾的动态变化给投资者的择时工作带来了更大挑战,其最直接的影响在于,我们很难从单一的宏观维度,构建出能够解释股市历次涨跌变化的指标。以股票市场为例,经济增长主要影响股市EPS,宏观流动性主要影响股市估值,从图表22中可以看出,股市在盈利和估值维度的主要矛盾在2015年至今具有阶段性的变化,且其切换频率不会过高,短约6个月,长可至近2年。也就是说,我们有可能会在1~2年的时间段内,即使准确的判断了盈利(估值)的变化,但由于错判或漏判了市场主要矛盾,造成整体做出错误的择时方向。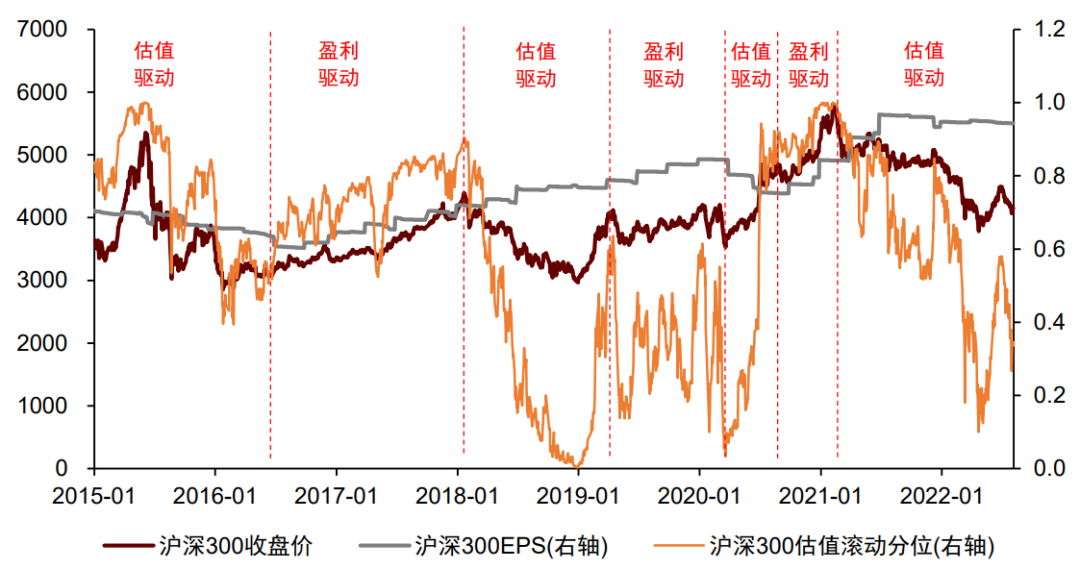
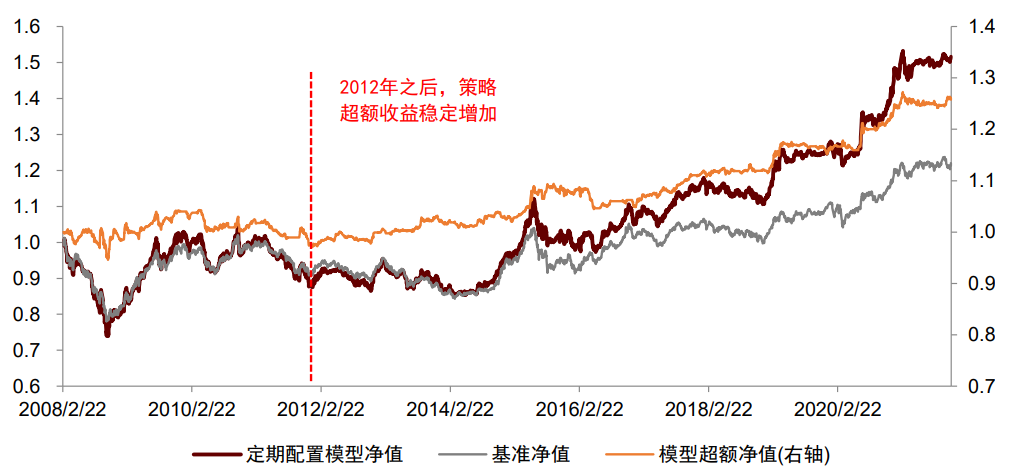
因此,我们认为对于宏观主要矛盾的判断,是宏观数据建模应用中的重要一环。承接上述案例,假设我们能准确判断未来盈利(估值)变化,并在图表X各阶段内,准确识别当时的宏观主要矛盾,在主要矛盾看好市场时,做多沪深300指数,在主要矛盾看空市场时,做空沪深300指数。从2015年至今,通过该方法我们可以获得3.61的累计净值,而若我们不进行主要矛盾的判断,单从盈利和估值的维度来进行择时,则2015年至今的累计净值分别为1.50和1.37,弱于加入主要矛盾判断的择时效果。从此可以看出,准确判断宏观主要矛盾,可以较为显著的增厚股市择时效果。图表23:准确判断宏观主要矛盾,可以较为显著的增厚择时效果
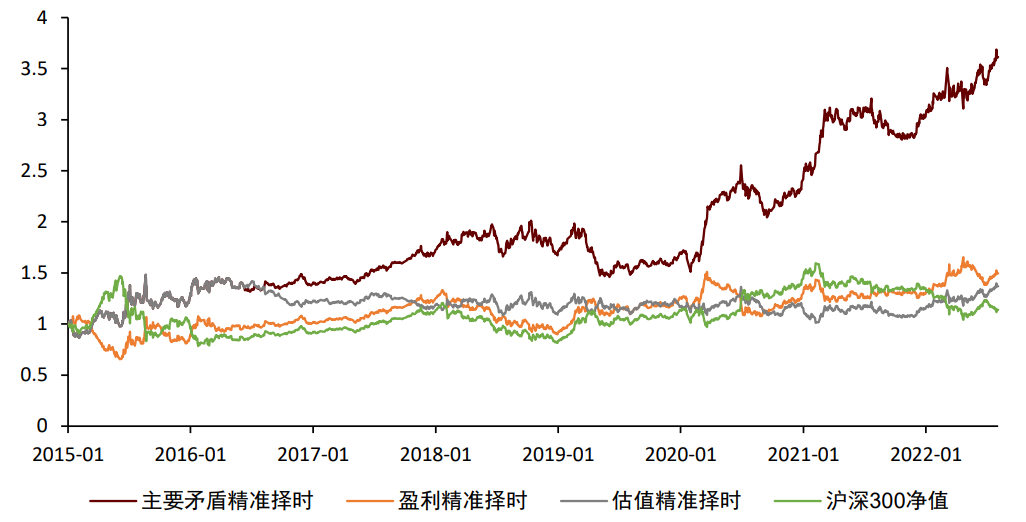
我们在前述报告《量化配置系列(10):如何利用市场主要矛盾辅助大势研判》中,介绍了两种宏观主要矛盾的判断方法,分别为敏感型行业法和文本分析法,感兴趣的投资者可参考我们前述报告。

宏观数据在实际投资中有着丰富的应用场景,本部分对业界常用的应用方式进行归纳,并展示中金量化团队的已有应用实践成果。
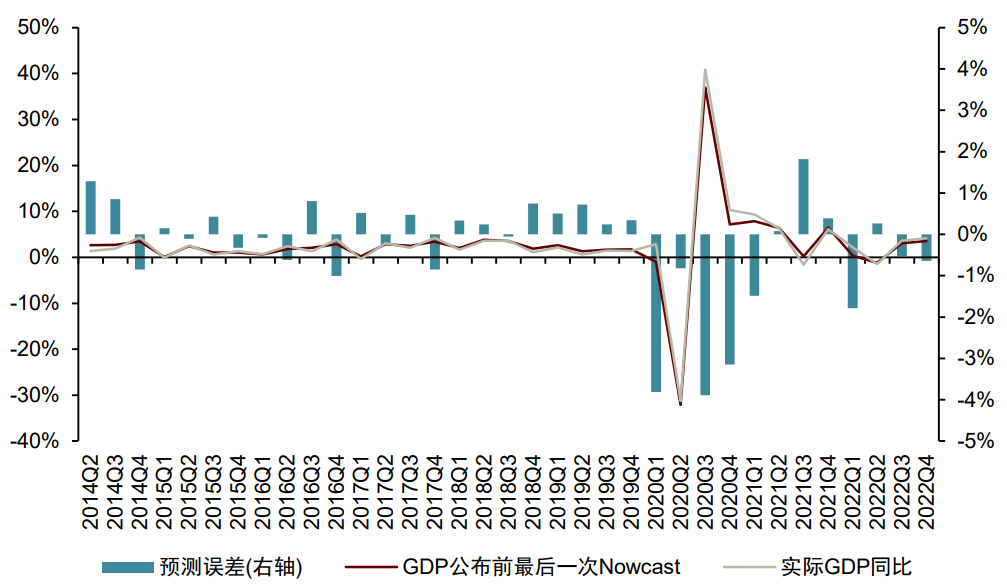
宏观数据的Nowcast模型是基于动态更新的高频宏观数据,对低频宏观数据的预期值进行实时播报的模型。目前最为典型的Nowcast模型是美国亚特兰大联储所构建的GDPNow模型。GDPNow的总体逻辑是在GDP支出法核算框架下 ,将GDP组成部分分解后,利用季度和月度数据对每一个子部分值进行预测,再利用子部分预测值合成GDP预测值。GDPNow使用的方法包括贝叶斯向量自回归模型(BVAR),因子增强自回归模型、桥梁模型(Bridge Model)等。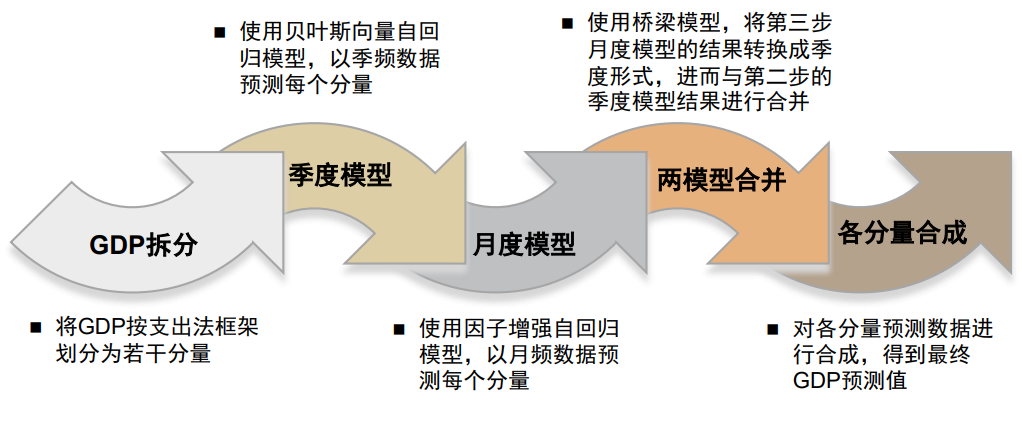
下图展示了GDPNow在历次GDP公布前的最后一次预测情况。可以看到,2020年因新冠疫情的因素导致美国GDP出现较大变动,使得GDPNow在该年的预测误差较大,而在其他年份,GDPNow表现出了相对较好的预测能力,平均预测误差仅为0.05%。从历史预测效果看,GDPNow具有一定的实际应用价值。
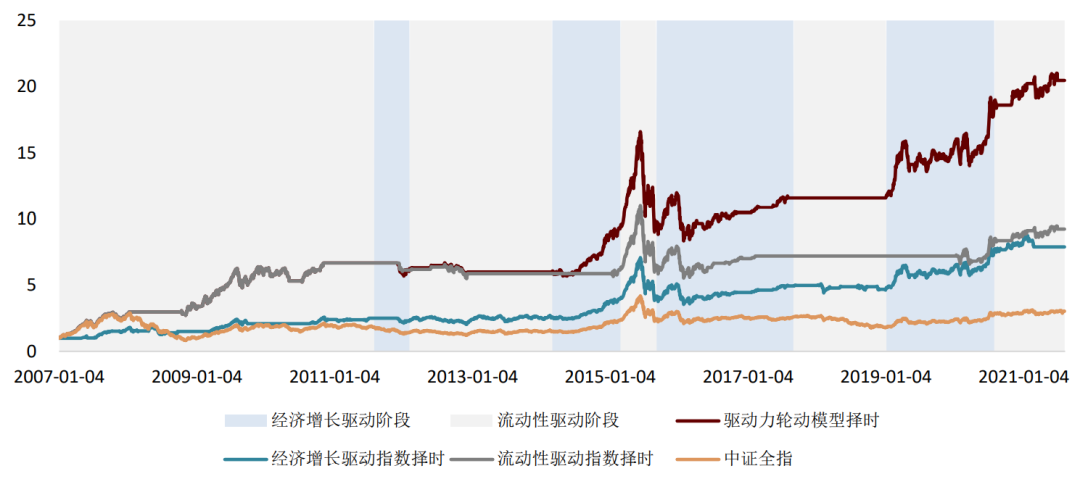
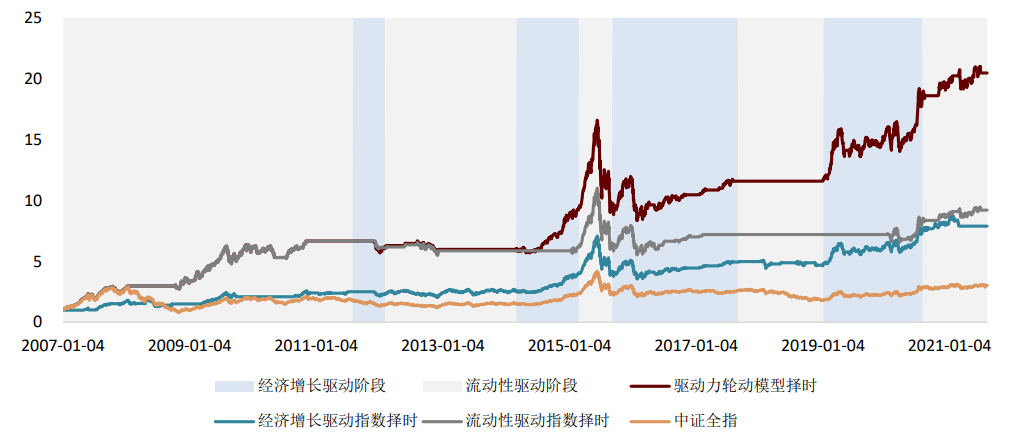
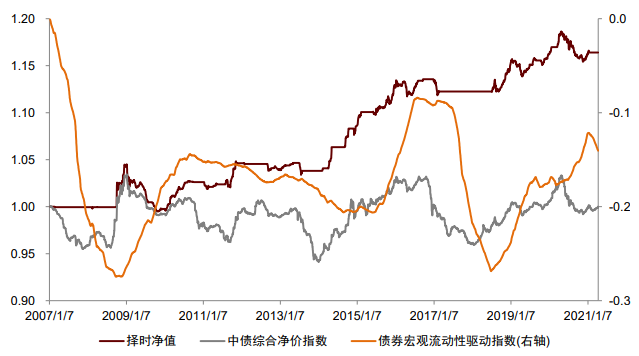
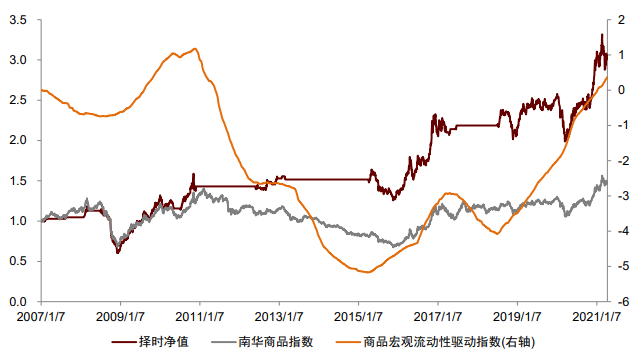
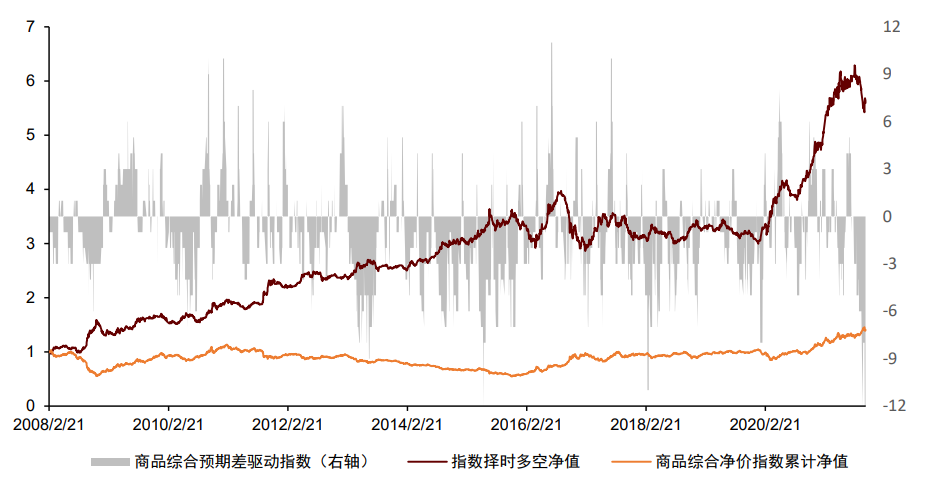
大类资产的走势一定程度受到宏观数据的影响,因此宏观数据在资产择时与配置中有广泛应用。我们认为宏观数据在择时与配置中有“两条逻辑线”和“一个关键点”,分别为:逻辑线1:经济指标实际值。经济指标的实际值更重要的意义在于刻画当前经济的运行状态和变化方向,如当前的通胀水平以及当前宏观流动性的变化方向。考虑到经济指标实际值的低频性、滞后性和状态刻画性,我们认为经济指标实际值在战略资产配置中有更为重要的应用意义,海外成熟的案例包括美林证券的美林时钟模型以及桥水公司的全天候模型等。我们在之前报告《量化配置系列(4):资产宏观流动性驱动指数及其应用》中,以我国的流动性产生过程为逻辑,打造了宏观流动性指标体系,并从中量化筛选对各资产有预测效果的有效指标,构建了用于预测我国股市、债市、商品未来走势的宏观流动性驱动指数。股市指数平均每年方向变动3.31次,债市指数3.56次,商品指数1.69次,频率接近战略配置需求,感兴趣的投资者可参考我们前述报告。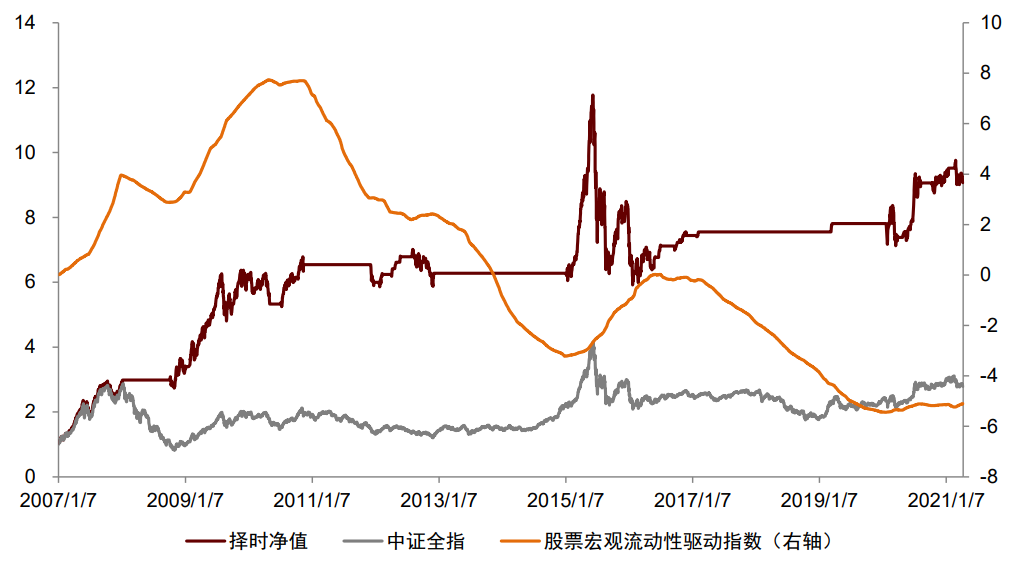
资料来源:Wind,中金公司研究部
逻辑线2:经济指标预期值。相比于经济指标实际值的低频性、滞后性和状态刻画性,经济指标预期值具有高频性、实时性和瞬时增量性,具体来说,经济指标预期值可以实现每天的实时动态更新,且经济指标实际值公布时的超预期情况是较大的瞬时信息增量。因此,我们认为经济指标预期值在战术资产配置中有更为重要的应用意义。我们在之前报告《量化配置系列(7):捕捉经济预期差,顺势配置资产》中,以国内重要经济指标的预期差数据为出发点,量化筛选对资产未来走势有显著影响的预期差数据,并构建了国内各资产的“预期差指数”,指数对国内股、债、商品短期的单资产择时以及多资产轮动具有良好的应用效果,感兴趣的投资者可参考我们前述报告。
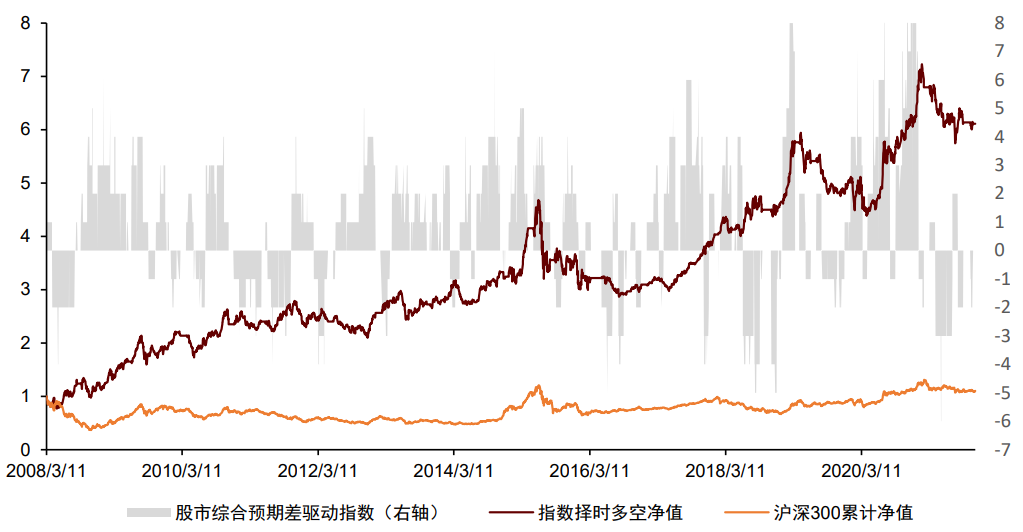
资料来源:Wind,中金公司研究部
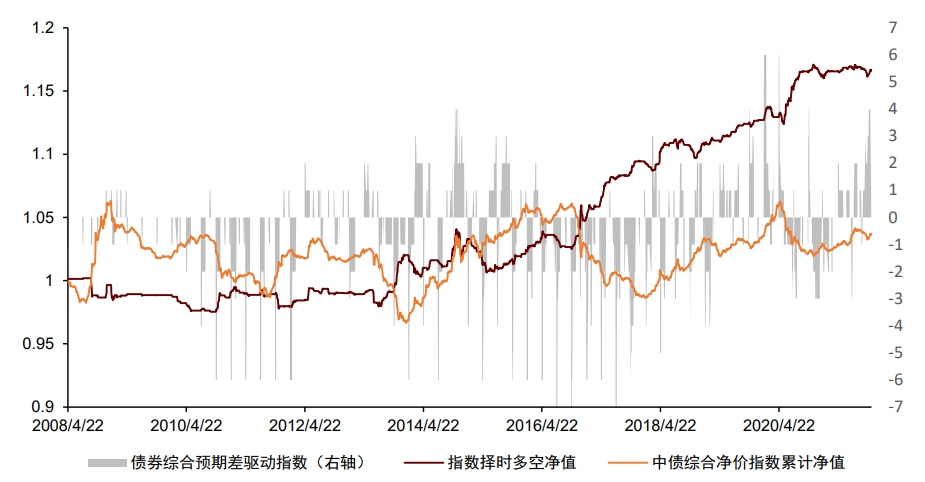
资料来源:Wind,中金公司研究部
关键点:判断宏观主要矛盾。如我们在前文中所述,经济增长、宏观流动性、通胀等因素,都会在特定情景下成为影响当时股票市场走势的主要宏观矛盾。当不同宏观维度对资产未来走势的指示方向相反时,我们可以以主要矛盾维度的观点方向为准,从而提升资产择时准确率,对宏观数据在择时与配置中的应用效果起到“锦上添花”的作用。具体做法可参考上一章节相关内容。
图表36:宏观数据在择时与配置中的“两条逻辑线”和“一个关键点”

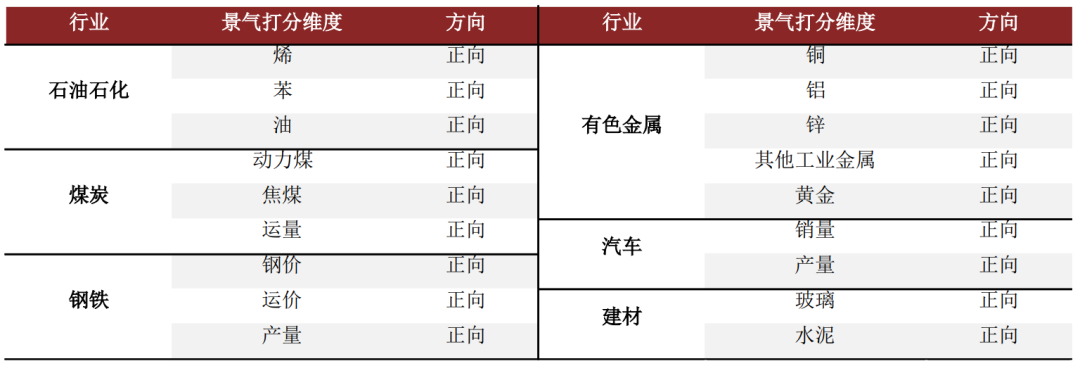
宏观数据实际值:在不同宏观状态下考虑更重要的行业打分指标。我们认为宏观状态会影响投资者判断行业未来表现时所考虑的信息维度,比如当前处于增长上行阶段,则投资者可能更关心产能利用率较高的行业,以在经济恢复过程中取得更高的营收弹性;而若当前是流动性上行阶段,则投资者可能更关心成长能力强的行业,因为更多的资金和投资利好高成长性公司的发展。换句话说,我们利用宏观数据判断当前经济变化状态,进而在行业打分时,对因子进行相应的超配与低配。图表37:在不同宏观经济状态下,给行业轮动因子不同的打分权重
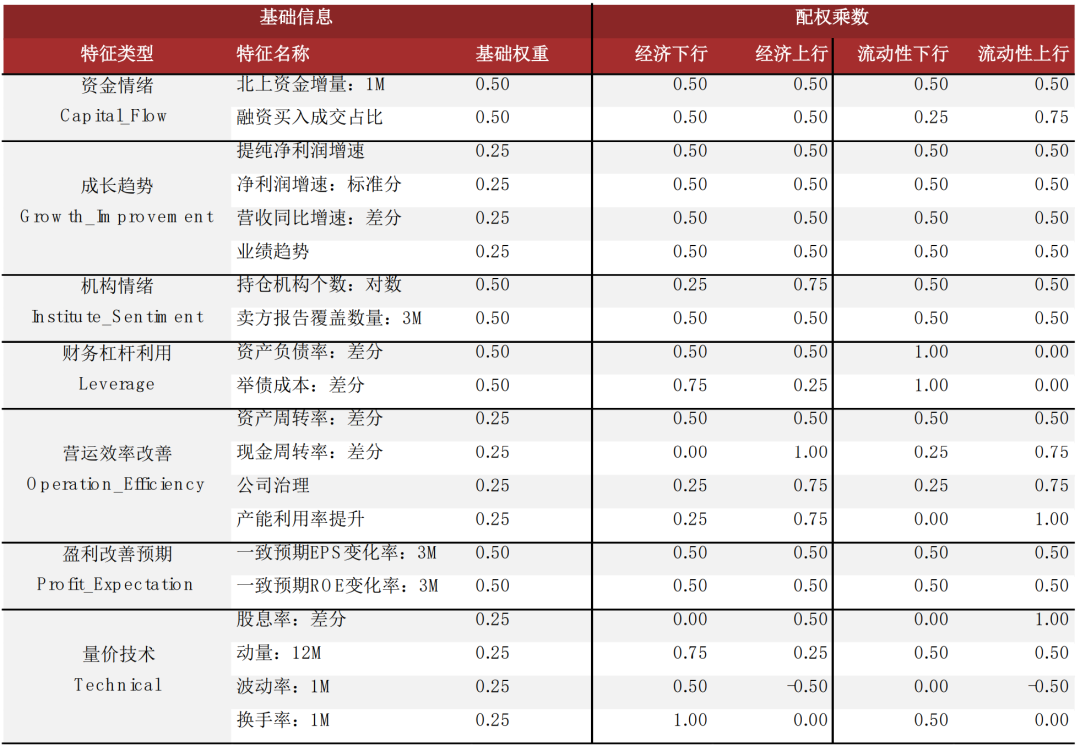
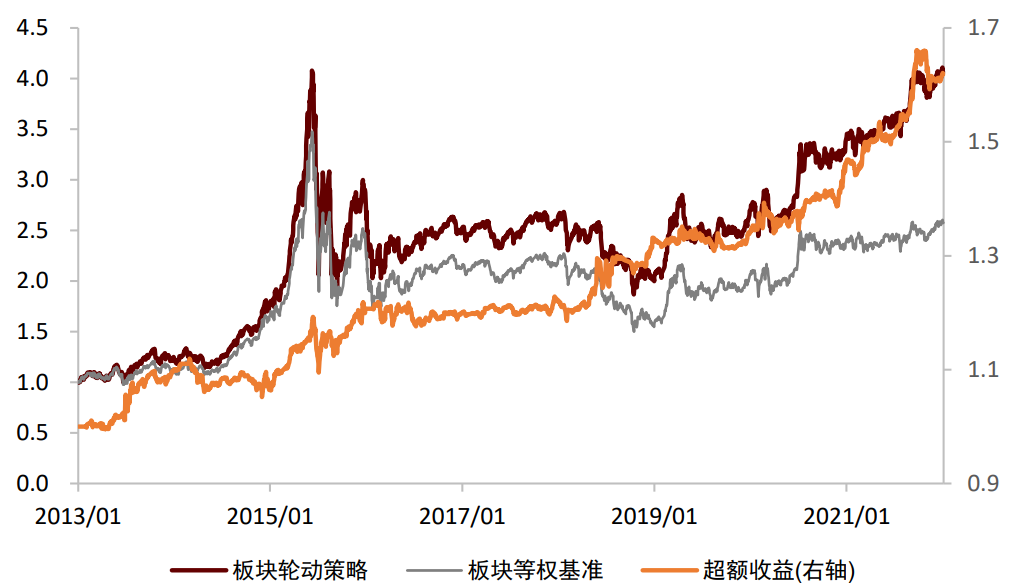
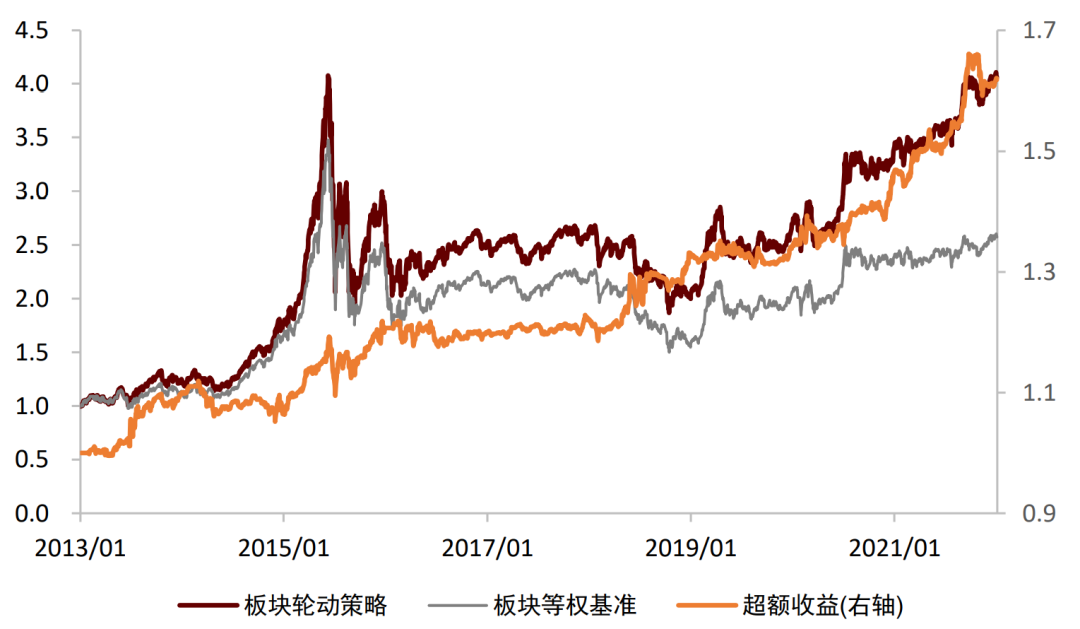
宏观数据预期值:选择当前超预期状态所利好的板块。我们认为近期公布宏观数据的超预期情况会影响投资者对于未来板块走势的观点,因此我们针对每个板块,量化筛选出了对其未来走势有显著预测效果的宏观预期数据,并根据宏观数据近期的超预期情况来判断各板块未来的相对表现。基于宏观超预期数据的板块轮动策略2013年至今超额收益稳定,日胜率较高。
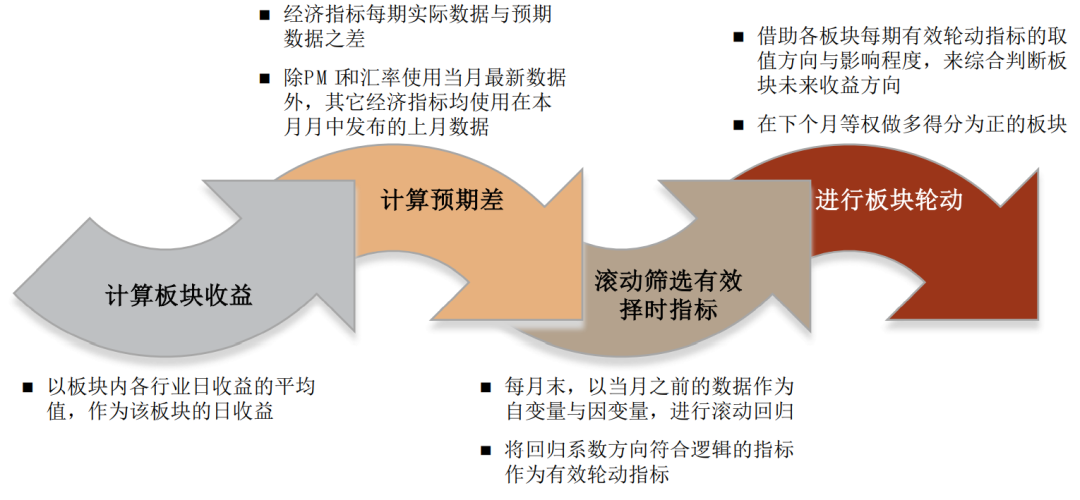
► 经济环境:我们测试了包括GDP同比增长率、CPI同比增长率,PPI同比增长率,规模以上工业增加值同比增长率,消费者信心指数、投资者信心指数、PMI、社消总额、社会融资规模增速等指标对成长/价值相对强弱的判断效果,其中有较显著预测能力的为社融同比、CPI-PPI、PMI三个指标。► 金融环境:我们测试了货币供应量、期限利差以及信用利差等指标对成长/价值相对强弱的判断效果,其中有较显著预测能力的为期限利差、M2-M1两个指标。
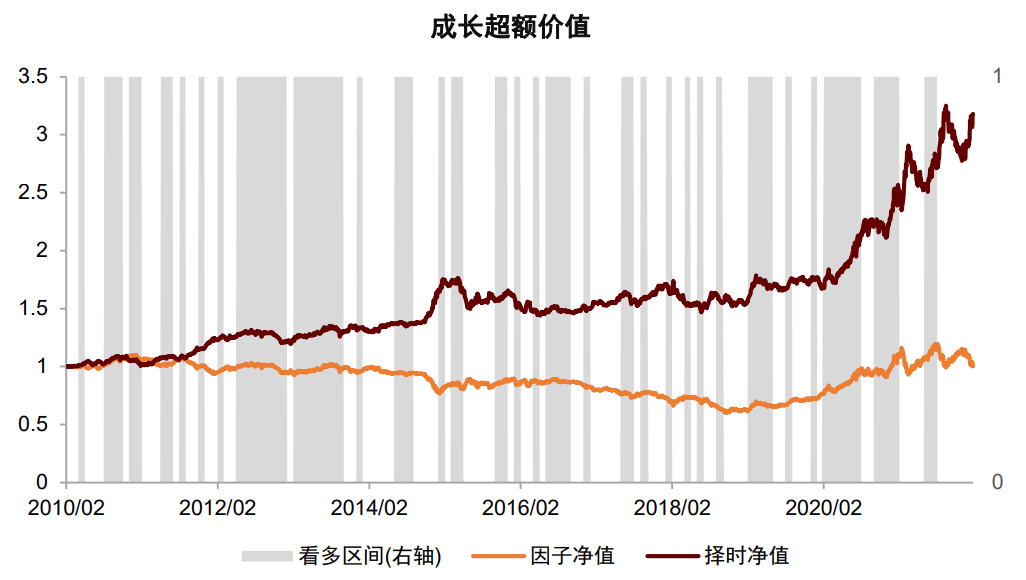
因子的有效性会受到宏观状态的影响。举例来说,经济增长指标超预期相对利好“进攻型”因子,原因在于经济增长超预期意味着企业整体的生产经营状况超预期,即公司的成长性与综合质量之前被低估,在未来会产生基本面预期修复的alpha;而通胀指标超预期相对利好“防守型”因子,原因在于通胀超预期意味着国家面临的比预期更高的通胀压力,会提升市场对于滞胀与经济衰退的预期,同时也会提升市场对于加息以对抗通胀的预期,利好偏防御的“防守型”因子。因此,我们可以利用宏观数据对选股因子进行择时。我们在之前报告《量化投资新趋势(1):经济预期在因子与板块配置中的应用》中,利用宏观数据的超预期情况,对中金量化风格因子体系中的10个因子进行择时,从结果看,宏观预期数据在轮动性较强的因子上有良好择时效果,在alpha性较强的因子上择时效果相对一般。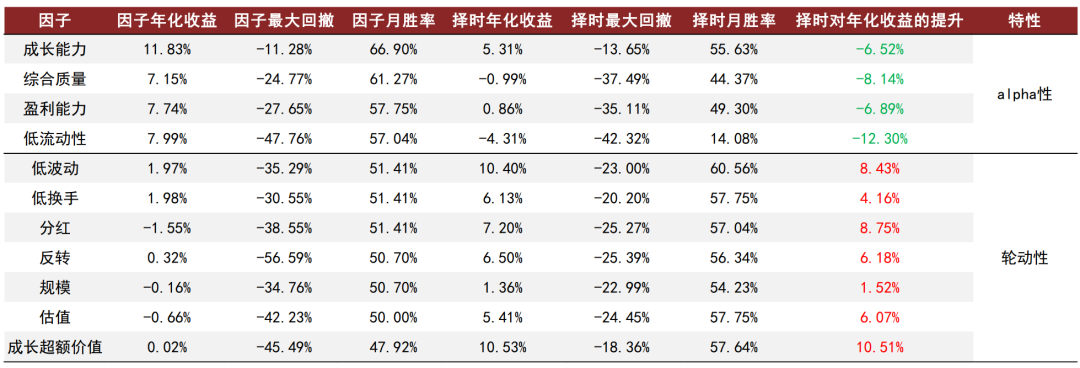
本文摘自:2023年2月15日已经发布的《量化配置系列(12):宏观数据建模应用手册》
分析员 宋唯实 SAC 执证编号:S0080522080003 SFC CE Ref:BQG075
分析员 周萧潇 SAC 执证编号:S0080521010006 SFC CE Ref:BRA090
分析员 刘均伟 SAC 执证编号:S0080520120002 SFC CE Ref:BQR365
分析员 王汉锋 SAC 执业编号:S0080513080002 SFC CE Ref:AND454
特别提示
本公众号不是中国国际金融股份有限公司(下称“中金公司”)研究报告的发布平台。本公众号只是转发中金公司已发布研究报告的部分观点,订阅者若使用本公众号所载资料,有可能会因缺乏对完整报告的了解或缺乏相关的解读而对资料中的关键假设、评级、目标价等内容产生理解上的歧义。订阅者如使用本资料,须寻求专业投资顾问的指导及解读。
本公众号所载信息、意见不构成所述证券或金融工具买卖的出价或征价,评级、目标价、估值、盈利预测等分析判断亦不构成对具体证券或金融工具在具体价位、具体时点、具体市场表现的投资建议。该等信息、意见在任何时候均不构成对任何人的具有针对性的、指导具体投资的操作意见,订阅者应当对本公众号中的信息和意见进行评估,根据自身情况自主做出投资决策并自行承担投资风险。
中金公司对本公众号所载资料的准确性、可靠性、时效性及完整性不作任何明示或暗示的保证。对依据或者使用本公众号所载资料所造成的任何后果,中金公司及/或其关联人员均不承担任何形式的责任。
本公众号仅面向中金公司中国内地客户,任何不符合前述条件的订阅者,敬请订阅前自行评估接收订阅内容的适当性。订阅本公众号不构成任何合同或承诺的基础,中金公司不因任何单纯订阅本公众号的行为而将订阅人视为中金公司的客户。
一般声明
本公众号仅是转发中金公司已发布报告的部分观点,所载盈利预测、目标价格、评级、估值等观点的给予是基于一系列的假设和前提条件,订阅者只有在了解相关报告中的全部信息基础上,才可能对相关观点形成比较全面的认识。如欲了解完整观点,应参见中金研究网站(http://research.cicc.com)所载完整报告。
本资料较之中金公司正式发布的报告存在延时转发的情况,并有可能因报告发布日之后的情势或其他因素的变更而不再准确或失效。本资料所载意见、评估及预测仅为报告出具日的观点和判断。该等意见、评估及预测无需通知即可随时更改。证券或金融工具的价格或价值走势可能受各种因素影响,过往的表现不应作为日后表现的预示和担保。在不同时期,中金公司可能会发出与本资料所载意见、评估及预测不一致的研究报告。中金公司的销售人员、交易人员以及其他专业人士可能会依据不同假设和标准、采用不同的分析方法而口头或书面发表与本资料意见不一致的市场评论和/或交易观点。
在法律许可的情况下,中金公司可能与本资料中提及公司正在建立或争取建立业务关系或服务关系。因此,订阅者应当考虑到中金公司及/或其相关人员可能存在影响本资料观点客观性的潜在利益冲突。与本资料相关的披露信息请访http://research.cicc.com/disclosure_cn,亦可参见近期已发布的关于相关公司的具体研究报告。
本订阅号是由中金公司研究部建立并维护的官方订阅号。本订阅号中所有资料的版权均为中金公司所有,未经书面许可任何机构和个人不得以任何形式转发、转载、翻版、复制、刊登、发表、修改、仿制或引用本订阅号中的内容。
本篇文章来源于微信公众号: 中金量化及ESG