►主要观点
本篇是“学海拾珠”系列第一百六十四篇,本文介绍了MemSum,一种基于强化学习的提取总结器,模型迭代地将句子选择到摘要中,考虑:(1) 句子的文本内容,(2)全局文本上下文, (3)已经提取的句子集的历史信息。凭借轻量级结构,MemSum 在长文档数据集(PubMed、arXiv 和 GovReport)上仍获得了最先进的测试集性能(ROUGE 分数)。
·不同尺度的特征提取器对于模型提取摘要的效果提升显著MemSum模型中包含局部句子编码器、全局句子信息编码器和已提取历史信息编码器三种不同尺度、不同目的的编码器,经过消融实验验证,这三种编码器都显示出了卓越性能,其中全局上下文编码器和提取历史编码又比局部句子编码器的作用更显著。提取历史编码器是MemSum能够达到SOTA的核心因素之一,经过验证,提取历史信息显著地降低了提取出的摘要的冗余度。与之前的模型不同之处在于,在MemSum中,停止选择句子也被当作一个独立的决策行为,相比于规定固定的句子数量或文本长度,以及在源文本中添加特殊停止标记的方法等,这种停止机制使得模型能够学习智能地选择摘要长度。核心内容摘选自Nianlong Gu,Elliott Ash和Richard H.R. Hahnloser 2022-05-22 在《Association for Computational Linguistics》上发表的文章《MemSum: Extractive Summarization of Long Documents Using Multi-Step Episodic Markov Decision Processes》文献结论基于历史数据与海外文献进行总结;不构成任何投资建议。自动文本摘要是将长文档自动总结为相对较短的文本,同时保留大部分信息的任务(Tas和Kiyani,2007)。文本摘要方法可分为生成式方法和提取式方法(Gambir和Gupta(2017),Nenkova和McKeown(2012))。给定一个由N个句子组成的有序列表形式的文档D,提取摘要旨在提取M(M<<N)个句子作为文档的摘要。提取方法生成的摘要往往在语法和语义上都比生成式摘要更可靠(Liu等人(2018),Liu和Lapata(2019a),Luo等人(2019),Liao等人(2020)),因为它们是直接从源文本中选择的。
提取式摘要通常被建模为两个连续阶段(Zhou等人,2018):(1)句子评分和(2)句子选择。在句子评分阶段,通过诸如双向RNN的神经网络(Dong等人(2018),Narayan等人(2018),Luo等人(2019),Xiao和Carenini (2019))或BERT(Zhang等人(2019),Liu和Lapata(2019b))来计算每个句子的亲和度得分(Affinity Score)。在句子选择阶段,句子是通过以下方式选择的:(1)根据每个句子的得分预测每个句子的标签(1或0),并选择标签为1的句子(Zhang等人(2019),Liu和Lapata (2019b),Xiao和Carenini (2019)),或(2)根据得分对句子进行排名,并选择排名前K的句子作为摘要(Narayan等人,2018),或(3)在不替换的情况下对句子进行顺序采样,其中剩余句子的归一化分数被用作采样可能性(Dong等人(2018),Luo等人(2019))。
在这些方法中,句子得分通常不会基于先前选择的句子的当前部分摘要来更新,这表明这些模型缺乏提取历史知识的能力。本文认为,不知道提取历史的摘要提取器很容易提取出冗余的摘要,因为无论以前是否选择过类似的句子,他们都会在摘要中重复添加得分高的句子。而且,冗余会导致ROUGE F1分数下降。
在本文中,作者提出将提取摘要建模为一个多步骤情景马尔可夫决策过程(MDP)。如图1所示,在一个阶段中的每个时间步长,我们定义了一个由三个子状态组成的句子状态:(1)句子的局部内容,(2)文档中句子的全局上下文,以及(3)提取历史信息,包括之前选择的无序句子集和剩余句子。在每个时间步,策略网络(agent)将当前句子状态作为输入,并生成用于选择停止提取过程或在候选摘要中选择剩余句子之一的动作的概率。与居于下一阶段的MDP模型(Narayan等人(2018),Dong等人(2018),Luo等人(2019))不同,在多步骤策略中,agent在选择动作之前,在每个时间步长更新提取历史。这种逐步状态更新策略使agent在选择句子时能够考虑部分摘要的内容。
为了有效地对局部和全局句子状态进行编码,本文设计了一种基于LSTM网络的提取系统(Hochreiter和Schmidhuber,1997)。为了对提取历史进行编码并做出决策,本文使用了相对低维度的注意力层(Vaswani等人,2017)。这些选择使我们的模型易于训练,并能够总结科学论文(Cohan等人(2018),Huang等人(2021))或报告(Huang等人,2021)等文。
本文的工作贡献如下:(1) 将提取摘要视为一种了解提取历史信息的多步骤情节MDP。(2) 研究表明,与没有历史意识的模型相比,提取历史信息使我们的模型能够提取更紧凑的摘要,并且对文档中的冗余表现得更稳健。(3) 在PubMed、arXiv(Cohan等人,2018)和GovReport(Huang等人,2021)数据集上,我们的模型优于提取和抽象摘要模型。(4) 最后,经过人工评估,MemSum摘要的质量高于竞争方法的摘要,冗余度较低是其突出优点。
在本文中,我们建议将提取摘要建模为多步情节Markov提取历史意识先前在NeuSum中被考虑(Zhou等人,2018),其中GRU将先前选择的句子编码为隐藏向量,然后用于更新剩余句子的分数,以衡量下一个选择的偏好。NeuSum不包含停止机制,因此它只能提取固定数量的句子,这可能是次优结果。此外,提取历史信息的潜在好处尚未被量化,因此这一想法在很大程度上仍未被充分探索。最近,基于BERT的提取器,如MatchSum(Zhong等人,2020),在从CNN/DM(Hermann等人,2015)数据集中提取相对较短的文档摘要时实现了SOTA性能。然而,以上的计算和空间复杂度(Huang等人, 2021)限制了它们用数千个tokens总结长文档的可扩展性,这在政府报告的科学论文中很常见。尽管具有高效注意力的大型预训练Transformer(Huang等人,2021)已适用于长文档的抽象摘要,但我们认为,一般来说,提取摘要更“忠实可靠”,这就是我们选择提取方法的原因。在具有最终状态(即摘要的最后一句)的多阶段任务中,梯度策略方法旨在最大化目标函数 ,其中
,其中 是从时间t+1到摘要结束所有阶段的累积奖励,在强化学习用于摘要提取的过程中,除了在所有阶段结束计算最终奖励r时,其余阶段的奖励都为0,因此
是从时间t+1到摘要结束所有阶段的累积奖励,在强化学习用于摘要提取的过程中,除了在所有阶段结束计算最终奖励r时,其余阶段的奖励都为0,因此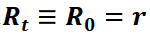 。奖励r通常表示为(Dong等人,2018):
。奖励r通常表示为(Dong等人,2018):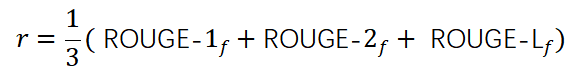
根据Williams在1992年提出的强化学习算法,策略梯度被定义为:
与通过一个动作提取整个摘要的单步状态MDP策略不同(Narayan等人(2018),Dong等人(2017),Luo等人(2019)),我们定义了一系列情节,即由多个时间步长组成的摘要的生成。在每个时间步t,对应于提取句子编号t,决策At是停止提取或者从剩余的句子中选择一个句子。可总结为如下模型:
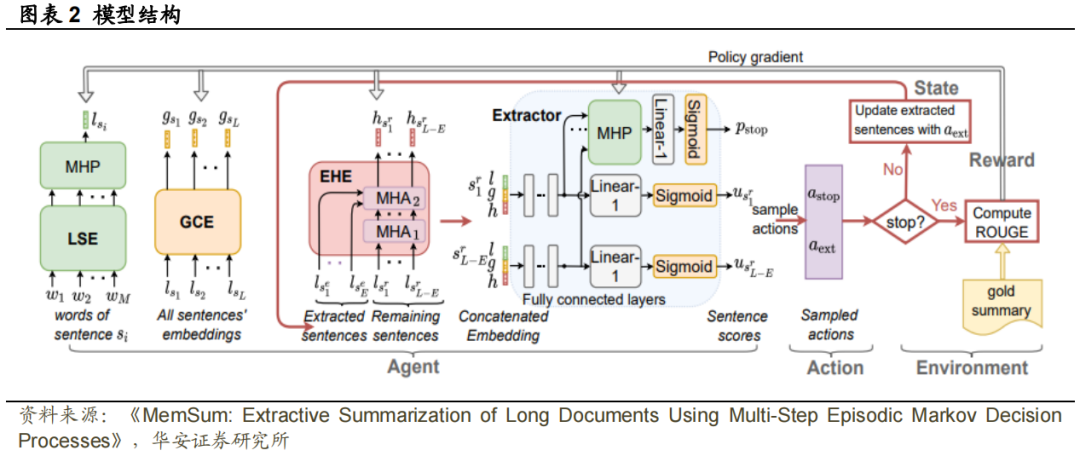
计算出条件概率后,结合3.1中的奖励分数计算和参数更新策略,模型的框架就很清晰了。本文中,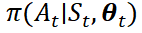 中的提供以下信息:(1) 句子的局部内容,(2) 文档中句子的全局上下文,(3) 当前提取历史。为了在状态中对这三个属性进行编码,我们分别使用局部句子编码器、全局上下文编码器和提取历史编码器。随后,该状态通过提取器映射为剩余句子中每一个的分数和停止概率。模型的总体框架如图表2所示。在局部句子编码器(LSE)中,首先使用词嵌入矩阵将句子中的有序单词
中的提供以下信息:(1) 句子的局部内容,(2) 文档中句子的全局上下文,(3) 当前提取历史。为了在状态中对这三个属性进行编码,我们分别使用局部句子编码器、全局上下文编码器和提取历史编码器。随后,该状态通过提取器映射为剩余句子中每一个的分数和停止概率。模型的总体框架如图表2所示。在局部句子编码器(LSE)中,首先使用词嵌入矩阵将句子中的有序单词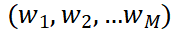 映射为词向量矩阵。随后,经过一个层的双向LSTM(Hochreiter和Schmidhuber,1997),再通过多头池化层(MHP)将它们映射到句子嵌入上(Liu和Lapata,2019a)。全局上下文编码器(GCE)由层双向循环神经网络组成,它以L个局部句子嵌入
映射为词向量矩阵。随后,经过一个层的双向LSTM(Hochreiter和Schmidhuber,1997),再通过多头池化层(MHP)将它们映射到句子嵌入上(Liu和Lapata,2019a)。全局上下文编码器(GCE)由层双向循环神经网络组成,它以L个局部句子嵌入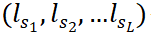 作为输入,并为每个句子生成嵌入,其中蕴涵了全局上下文信息,例如句子在文档中的位置和相邻句子的信息。提取历史编码器(EHE)对已提取信息进行编码,并为每个剩余句子产生提取历史嵌入。EHE由一堆个相同的层组成。在一个层中,有两个多头注意力子层,如Vaswani等人(2017)中的transformer解码器结构。一个子层用于在剩余句子的局部嵌入中执行多头自注意(MHA),以便每个剩余句子都能捕捉到其他剩余句子提供的上下文。另一个注意力子层用于对提取的句子的嵌入施加多头注意力,以使每个剩余的句子能够关注所有提取的句子。两个注意力子层(每个剩余句子一个)的输出充分提取了当前摘要句子和剩余句子的上下文信息。EHE的第
作为输入,并为每个句子生成嵌入,其中蕴涵了全局上下文信息,例如句子在文档中的位置和相邻句子的信息。提取历史编码器(EHE)对已提取信息进行编码,并为每个剩余句子产生提取历史嵌入。EHE由一堆个相同的层组成。在一个层中,有两个多头注意力子层,如Vaswani等人(2017)中的transformer解码器结构。一个子层用于在剩余句子的局部嵌入中执行多头自注意(MHA),以便每个剩余句子都能捕捉到其他剩余句子提供的上下文。另一个注意力子层用于对提取的句子的嵌入施加多头注意力,以使每个剩余的句子能够关注所有提取的句子。两个注意力子层(每个剩余句子一个)的输出充分提取了当前摘要句子和剩余句子的上下文信息。EHE的第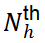 层的最终输出构成提取历史嵌入,长度与剩余句子数量相同。Extractor计算每个剩余句子的分数,并输出提取停止概率。作为提取器的输入,我们通过连接局部句子嵌入
层的最终输出构成提取历史嵌入,长度与剩余句子数量相同。Extractor计算每个剩余句子的分数,并输出提取停止概率。作为提取器的输入,我们通过连接局部句子嵌入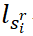 、全局上下文嵌入
、全局上下文嵌入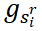 和提取历史嵌入
和提取历史嵌入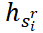 ,为剩余句子
,为剩余句子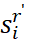 中的每一个形成聚合嵌入。如图2所示,为了产生得分
中的每一个形成聚合嵌入。如图2所示,为了产生得分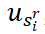 ,剩余句子
,剩余句子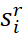 的聚合嵌入通过ReLU激活函数传递到全连接层,然后通过Linear-1层和sigmoid函数映射为标量。注意,相同的全连接层同样适用于所有剩余的句子。Extractor可以根据剩余句子的状态来学习停止策略。因此,我们将MHP应用于所有剩余句子的隐藏向量,以输出单个向量。然后,该向量被传递到具有sigmoid函数的线性层,产生停止概率
的聚合嵌入通过ReLU激活函数传递到全连接层,然后通过Linear-1层和sigmoid函数映射为标量。注意,相同的全连接层同样适用于所有剩余的句子。Extractor可以根据剩余句子的状态来学习停止策略。因此,我们将MHP应用于所有剩余句子的隐藏向量,以输出单个向量。然后,该向量被传递到具有sigmoid函数的线性层,产生停止概率 。
。
正在训练过程中,每一次迭代,都对一个阶段(情节)的所有时间步 t 的最终奖励 r 和决策概率𝜋(𝐴𝑡 ∣ 𝑆𝑡,𝜽𝑡)。例如在某个阶段,已提取了 T 个句子作为摘要,当前情节表现为:(𝑆0, 𝑠𝑎0, … , 𝑆𝑇−1, 𝑠𝑎𝑇−1, 𝑆𝑇, 𝐴stop , 𝑟),其中𝑆𝑇表示聚合状态,𝑆𝑎𝑇表示对于第 T 个句子的选择决策,𝐴stop 表示提取在时间步长 T 处停止。此外,为了鼓励模型尽可能提取紧凑的摘要,我们令奖励 r 乘上惩罚系数1/(𝑇 + 1) (Luo 等人,2019),因此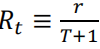 。
。
图表 3 中的算法总结了 MemSum 的训练过程。我们将提取历史嵌入初始化为0,因为在 t=0 时没有提取任何句子。𝐸𝑡表示截至时间步长 t 已提取到摘要中的句子数量。此外,不是按照当前策略𝜋(∙ ∣ ∙ , 𝜽𝑡)完成当前阶段的采样,而是从具有高ROUGE 分数的一组𝔼𝑝集中采样一个情节,这使得模型能够快速地从最优策略中学习并快速地收敛。在本节中,我们报告了模型的实现细节和用于训练和评估的数据集。数据集:PubMed和arXiv数据集中要总结的文档(Cohan等人,2018)是科学论文的全文,gold summary是相应的标准摘要。Zhong等人(2020)通过用论文引言代替整篇文档的方法,发布了PubMed数据集的截断版本(为了简单起见,记为PubMed-trunc)。Gov Report数据集(Huang等人,2021)包含美国政府报告和专家撰写的黄金摘要。除PubMed-trunc外,所有其他数据集都包含比主流数据集CNN/DM更长的文档,见图表4。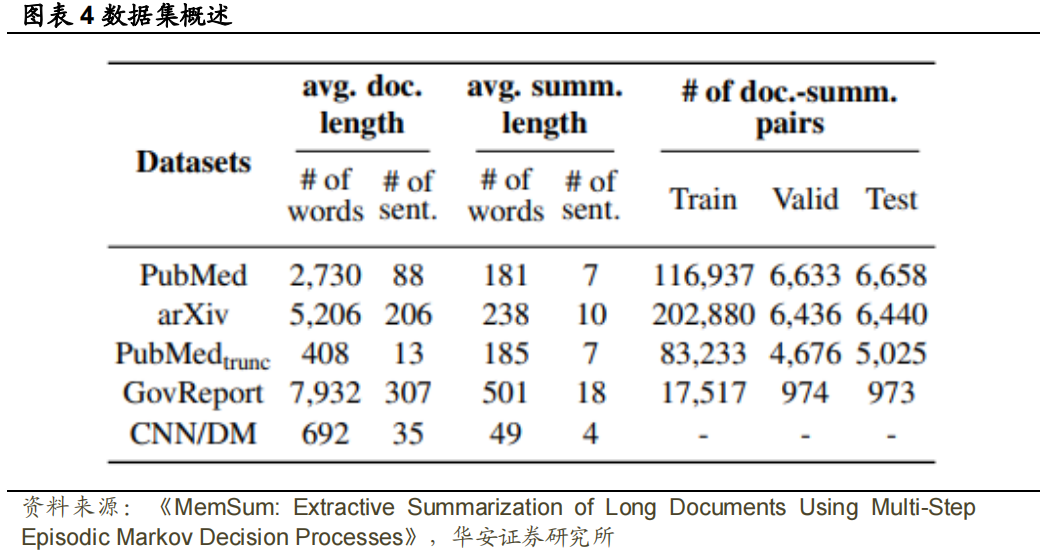
Baseline:提取式方法的baseline包括Lead(直接使用前几句作为摘要)(Gidiotis和Tsoumakas,2020)、SummaRuNNer(Nallapati et al.,2017)、Atten-Cont(Xiao和Carenini,2019)、Sent CLF和Sent PTR(Pilault et al.,2020),MatchSum(Zhong et al.,2019),以及我们在数据集上训练的NeuSum模型(Zhou et al.,2018)。抽象摘要模型包括PEGASUS(Zhang等人,2020)、BigBird(Zaheer等人,2017)、Dancer(Gidiotis和Tsoumakas,2020),以及Hepos(Huang等人,2021),其使用大规模预训练的BART模型(Lewis等人,2020)达成了长文档摘要的最先进表现,该模型具有高效记忆的注意力编码方案,包括局部敏感哈希(Kitaev等人,2020)(Hepos-LSH)和Sinkhorn注意力(Hepos-Sinkhorn)。我们还介绍了基于贪婪方法(Nallapati等人,2017)的Extractive Oracle模型,该方法从文档中顺序选择最大限度地提高所选句子的R-1和R-2平均值的句子。实验细节:我们使用预先训练的200维的Glove模型(Pennington等人,2014)计算局部句子嵌入,在训练期间保持单词嵌入固定。对于LSE,我们使用了𝑁𝑙=2个BiLSTM 层,对于 GCE,使用了𝑁𝑔=2。对于 EHE,我们使用𝑁ℎ=3 个注意力层,注意力头设置为8,前馈层的维度设置为 1024;dropout 设置为 0.1。Extractor 由两个全连接隐藏层组成,输出维度分别为 2d 和 d。我们使用 Adam 优化器训练我们的模型,其中𝛽1=0.9,𝛽2=0.999(Kingma 和Ba,2015),固定学习率𝛼 = 1𝑒−4,权重衰减1𝑒−6。当验证集上模型表现开始下降时,训练中止。提取句子的具体过程如下:在计算剩余句子的得分𝑢𝑠𝑖Γ和停止概率𝑝𝑠𝑡𝑜𝑝后,如果𝑝𝑠𝑡𝑜𝑝≥𝑝𝑡ℎ𝑟𝑒𝑠或达到提取句子的最大容许数量𝑁𝑚𝑎𝑥后,停止提取,否则模型选择得分最高的句子。我们在八个 RTX 2080-Ti GPU 上完成了训练。在验证集上,我们选择了每个模型的最佳 check point,并确定了最佳𝑁𝑚𝑎𝑥和停止阈值 。对于 Pubmed、arXiv、Pubmed-trunc 和 Gov Report,𝑁𝑚𝑎𝑥分别设置为 7、5、7 和 22,
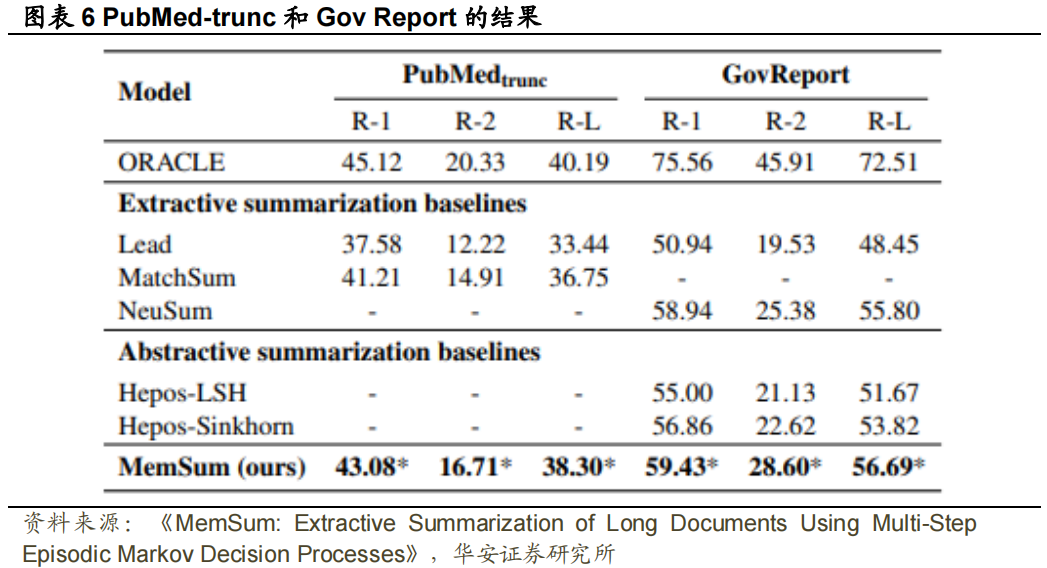
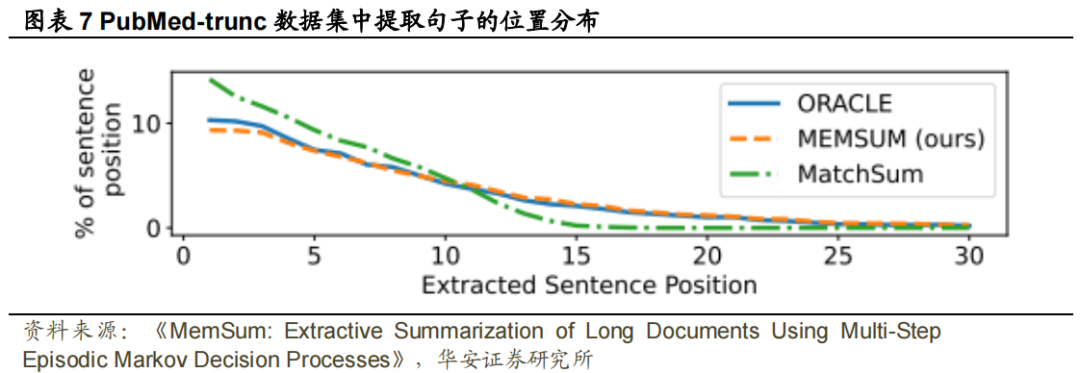
。对于 Pubmed、arXiv、Pubmed-trunc 和 Gov Report,𝑁𝑚𝑎𝑥分别设置为 7、5、7 和 22,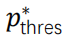 分别设置为 0.6、0.5、0.8 和 0.6。Evaluation:我们使用 F1-ROUGE(Lin,2004)评估我们的模型的性能,包括用于评估unigram、bigram和最长公共子序列的ROUGE-1,2和L分数。我们还在第5.4节中报告了人为评估的结果。本节展示了各种提取摘要任务的结果,并通过消融实验分析了模型中不同模块的贡献。通过与PubMed和arXiv数据集上的baseline进行比较,我们观察到能够利用提取历史信息的模型,如NeuSum和我们的MemSum,表现明显优于其他模型,从而揭示了综合提取历史信息的有效性。MemSum也显著优于NeuSum,这表明本文提出的模型对历史信息的利用率更高,我们将其归因于以下因素:(1) 在MemSum中,我们将停止提取也视为一种行为,此时策略网络输出停止概率。因此,MemSum能够根据提取历史在最佳时间步自动停止提取,而NeuSum只能提取预定义数量的句子;(2) 使用策略梯度强化学习,我们可以直接训练MemSum以最大化ROUGE分数,而在NeuSum中,损失被设置为模型计算的句子分数和每一步的ROUGE得分之间的KL偏差,这不太直观。我们在5.4中通过人类评估进一步比较了MemSum和NeuSum。我们观察到,模型在PubMed-trunc数据集上的ROUGE分数表现明显低于在PubMed数据集上的表现,Extractive Oracle的R-1下降了16.87,MemSum的R-1降低了6.23,这充分表明文章的引言不足以代替全文生成接近基本事实的摘要。即便如此,我们的模型仍然显著优于PubMed-trunc上训练的MatchSum,我们将其归因于MatchSum将引言进一步截断为512个token,因为它需要使用Bert计算文档嵌入。因此,MatchSum主要从文档的前15个句子中提取句子,而MemSum产生了与Extractive Oracle类似的提取句子位置分布,如图表7所示。因此,提取摘要是一项不寻常的任务,在总结短文本方面效果良好的模型(例如,CNN/DM)可能无法推广到长文本摘要领域。根据ROUGE分数衡量,MemSum的表现也显著优于最先进的抽象摘要模型Hepos,尤其是在Gov Report数据集上。MemSum和Hepos-Sinkhorn在Gov Report数据集(图表8)上生成的摘要的比较结果与ROUGE分数的比较结果一致,表明MemSum抽取的摘要比Hepos-Sinkhorn产生的摘要更准确,并且与Gold Summary有更高的重叠。我们认为,与其他数据集相比,Gov Report数据集中的Gold Summary具有更高的“提取性”,这在一定程度上可能是由于技术语言难以在不改变含义的情况下进行抽象总结。Gov Report数据集(图表6)上Extractive Oracle的ROUGE分数高于PubMed和arXiv数据集(图表5),这一事实证明了这一点。因此,由于Gov Report摘要的严谨性要求,提取式摘要可能比抽象式摘要更合适。
分别设置为 0.6、0.5、0.8 和 0.6。Evaluation:我们使用 F1-ROUGE(Lin,2004)评估我们的模型的性能,包括用于评估unigram、bigram和最长公共子序列的ROUGE-1,2和L分数。我们还在第5.4节中报告了人为评估的结果。本节展示了各种提取摘要任务的结果,并通过消融实验分析了模型中不同模块的贡献。通过与PubMed和arXiv数据集上的baseline进行比较,我们观察到能够利用提取历史信息的模型,如NeuSum和我们的MemSum,表现明显优于其他模型,从而揭示了综合提取历史信息的有效性。MemSum也显著优于NeuSum,这表明本文提出的模型对历史信息的利用率更高,我们将其归因于以下因素:(1) 在MemSum中,我们将停止提取也视为一种行为,此时策略网络输出停止概率。因此,MemSum能够根据提取历史在最佳时间步自动停止提取,而NeuSum只能提取预定义数量的句子;(2) 使用策略梯度强化学习,我们可以直接训练MemSum以最大化ROUGE分数,而在NeuSum中,损失被设置为模型计算的句子分数和每一步的ROUGE得分之间的KL偏差,这不太直观。我们在5.4中通过人类评估进一步比较了MemSum和NeuSum。我们观察到,模型在PubMed-trunc数据集上的ROUGE分数表现明显低于在PubMed数据集上的表现,Extractive Oracle的R-1下降了16.87,MemSum的R-1降低了6.23,这充分表明文章的引言不足以代替全文生成接近基本事实的摘要。即便如此,我们的模型仍然显著优于PubMed-trunc上训练的MatchSum,我们将其归因于MatchSum将引言进一步截断为512个token,因为它需要使用Bert计算文档嵌入。因此,MatchSum主要从文档的前15个句子中提取句子,而MemSum产生了与Extractive Oracle类似的提取句子位置分布,如图表7所示。因此,提取摘要是一项不寻常的任务,在总结短文本方面效果良好的模型(例如,CNN/DM)可能无法推广到长文本摘要领域。根据ROUGE分数衡量,MemSum的表现也显著优于最先进的抽象摘要模型Hepos,尤其是在Gov Report数据集上。MemSum和Hepos-Sinkhorn在Gov Report数据集(图表8)上生成的摘要的比较结果与ROUGE分数的比较结果一致,表明MemSum抽取的摘要比Hepos-Sinkhorn产生的摘要更准确,并且与Gold Summary有更高的重叠。我们认为,与其他数据集相比,Gov Report数据集中的Gold Summary具有更高的“提取性”,这在一定程度上可能是由于技术语言难以在不改变含义的情况下进行抽象总结。Gov Report数据集(图表6)上Extractive Oracle的ROUGE分数高于PubMed和arXiv数据集(图表5),这一事实证明了这一点。因此,由于Gov Report摘要的严谨性要求,提取式摘要可能比抽象式摘要更合适。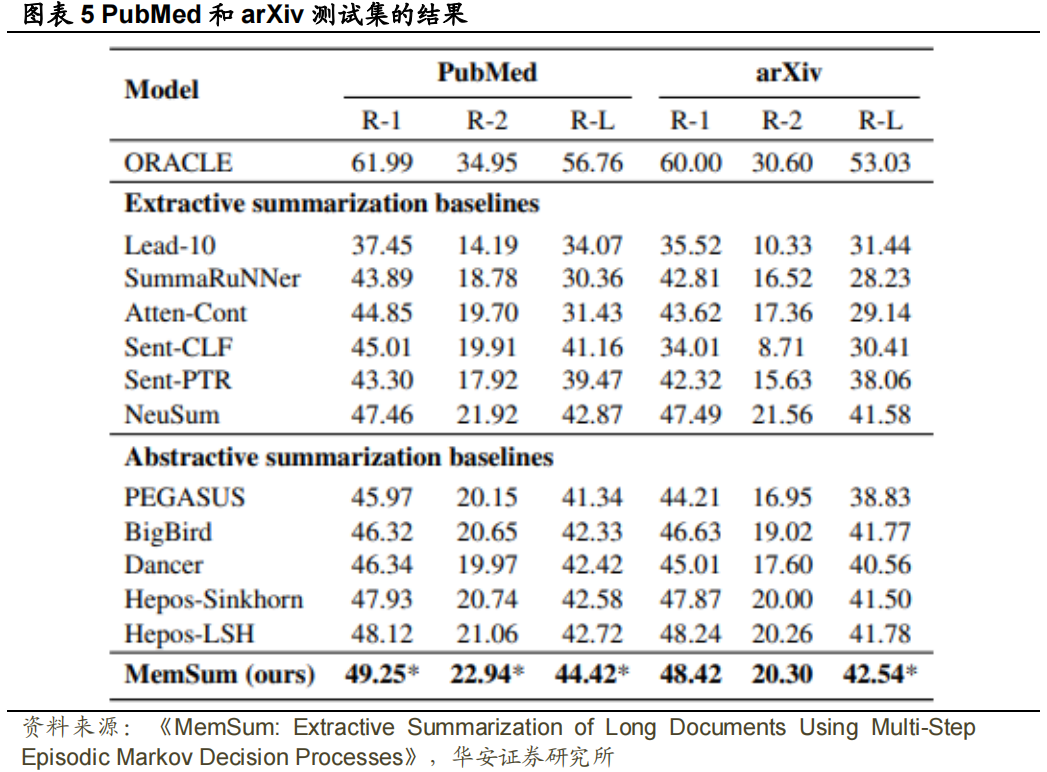
我们通过将完整的 MemSum 模型与以下结构变化进行比较来进行消融研究:(1) 不使用 LSE,在没有 LSE 的模型中,通过用单词嵌入的简单平均值代替基于 Bi-LSTM 的 LSE 来获得局部句子嵌入;(2) 不使用 GCE;(3) 不使用 EHE,其中我们删除 EHE,一步计算所有句子的分数,并根据 BanditSum 策略对句子进行采样(Dong 等人,2018);(4) 使用 GRU-EHE 代替注意力 EHE,其中我们在每个时间步长使用 GRU 对先前提取的句子进行编码,并使用最后一个隐藏状态作为所有剩余句子的提取历史嵌入,如周(2018)等人所述。同时,我们还测试了两种采用不同停止机制的变体:(1)不使用自动停止,即不基于𝑝𝑠𝑡𝑜𝑝 自动停止提取,而是提取固定数量的句子;(2) 带有“STOP”的MemSum,在文档中插入一个特殊的停止语句(例如“STOP”),并在模型提取该语句后停止提取。不同模块的贡献:去除 GCE 比去除 LSE 对性能的影响更大(图表 9),这表明在我们的 MemSum 框架中,对全局上下文信息建模比对局部句子信息建模更重要,这与在 Atten-Cont(Xiao和 Carenini,2019)模型中对局部句子信息建模更重要的结果形成了对比。此外,我们观察到,在去除 EHE 时,性能显著下降,但MemSum和使用GRU-EHE的MemSum之间没有显著差异,这表明EHE是必要的,但我们的MemSum策略并不强烈依赖于该模块的特定结构(例如,基于注意力或基于RNN)。停止机制的影响:与MemSum相比,不带自动停止的MemSum获得了更低的ROUGE分数,这揭示了在MemSum架构中自动停止的必要性。同时,带有“STOP”的MemSum生成的摘要中提取的句子较少(平均为3.9句,而不是6.0句),ROUGE分数显著较低。我们将这种减少归因于模型从选择结束的特殊停止句中获得了可预测的积极回报,这导致模型对这一最终行动的偏好,并增加了过早采取这一行动的可能性。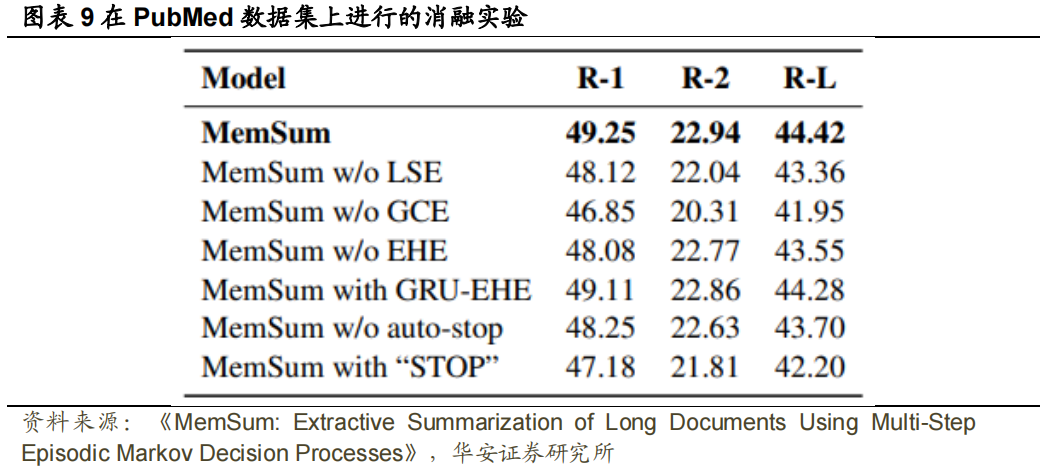
我们假设提取历史让MemSum避免与当前部分摘要中现有句子相似的句子,直观地模仿人类在提取摘要文档时的行为。为了验证这一点,我们创建了一个冗余的PubMed数据集,在其中我们重复了文档中的每一句话,复制的句子紧跟在原始句子之后。在这个数据集上,我们训练和测试了MemSum和没有EHE的MemSum (无历史意识),并根据ROUGE分数和平均重复百分比(定义为摘要中所有提取句子中重复句子的平均百分比)比较了不同的模型。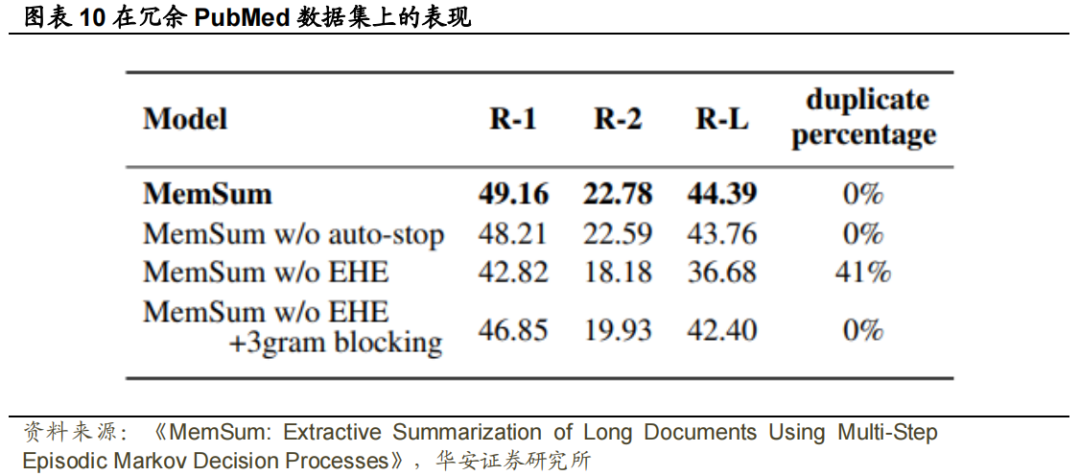
如图表10所示,对于不含EHE的MemSum,提取的摘要中平均有41%的句子重复。随着高重复率的出现,ROUGE评分显著下降。相比之下,当比较PubMed数据集(图表5)和冗余PubMed数据库(图表10)上的MemSum结果时,具有历史意识的完整MemSum模型的性能只受到轻微影响。同时,使用Trigram Blocking方法跳过与已有句子中tri-gram以上重复的句子(Liu和Lapata,2019b)也成功地避免了重复的句子。然而,与Trigram Blocking相关的ROUGE评分显著低于具有提取历史意识的MemSum评分。总之,历史感知MemSum模型在没有明确的人类指导或相关规则的情况下,自发地学习了一种避免冗余句子的优化策略,从而显示出更好的性能。我们让MemSum总结从冗余PubMed数据集的测试集中采样的文档,并监测Extractor在每个提取步骤中产生的句子分数。结果如图表11所示。当t=0时,第10个句子获得了最大分数,因此被选入摘要。在时间步1,我们注意到第11句是第10句的复制句,其得分接近于零。其他选定的句子及其后的句子也是如此,这表明提取器有能力避免重复。由于EHE对提取顺序和句子位置信息不敏感,如3.3所述,我们可以得出结论,完整的MemSum通过评估所选句子和剩余句子之间的相似性来避免冗余,而不是通过“记住”所选句子的位置。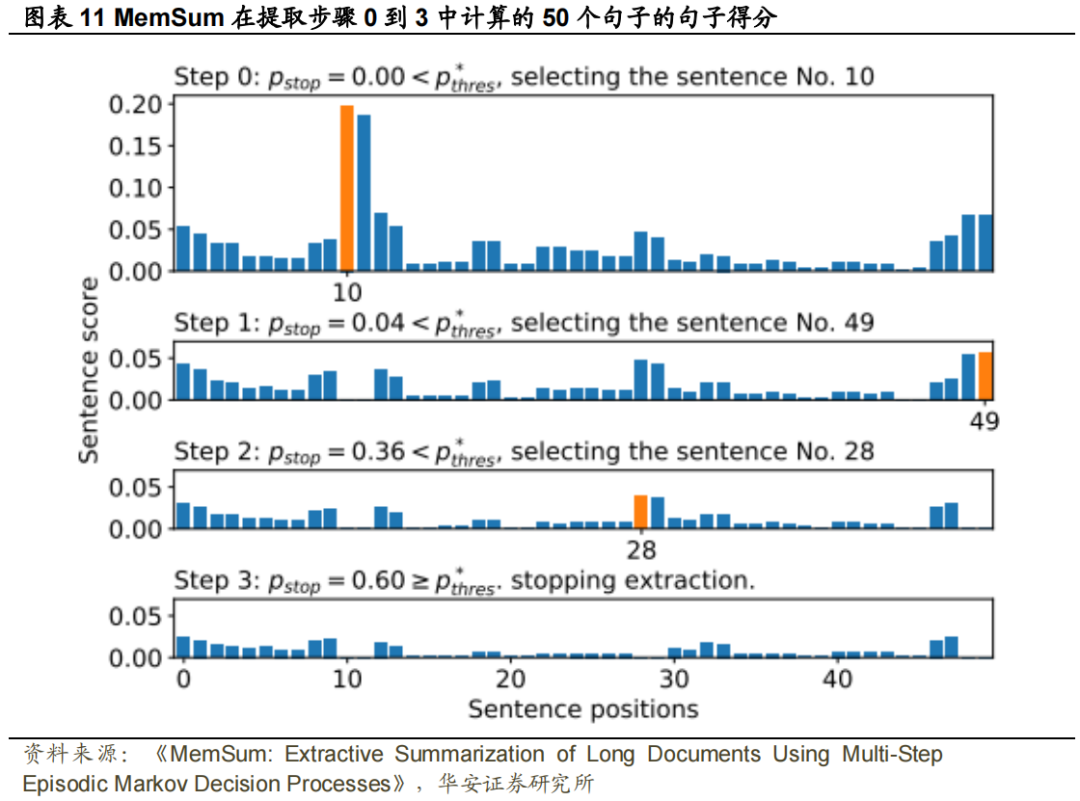
我们在吴和胡(2018)、董等人(2018)和之后进行了评估,对于从PubMed数据集的测试集中采样的每个文档,我们提供了一个参考摘要,并要求志愿者根据三个标准对两个模型生成的一对随机排序的摘要进行排序:非冗余、覆盖率和总体质量。更好的模型将被排名为#1,下一个被排名为#2,如果两个模型都提取了相同的摘要,那么它们都将获得#1排名。在实验1中,我们比较了总是提取7个句子的NeuSum和由于自动停止而提取灵活数量的句子的MemSum。在实验2中,我们通过使不使用自动停止的MemSum来提取7个句子,从而对提取的句子数量的差异进行了贴现。图表12报告了两个实验的评估结果。MemSum和无自动停止的MemSum在非冗余方面的排名均显著高于NeuSum(p<0.005),并实现了更好的平均整体质量。就字数而言,在两个实验中,MemSum产生的总和比NeuSum更短,尽管两个模型在实验2中提取的句子数量相同。这些结果表明,即使没有自动停止机制,MemSum的冗余避免也特别好。NeuSum在覆盖率方面稍好的性能需要与提取明显更长的摘要进行权衡。注意,NeuSum和我们的模型都没有经过训练来优化提取句子的顺序。因此,我们没有使用取决于句子顺序的流利度作为人类评价的指标。提高摘录摘要的流畅性将是我们未来研究的主题。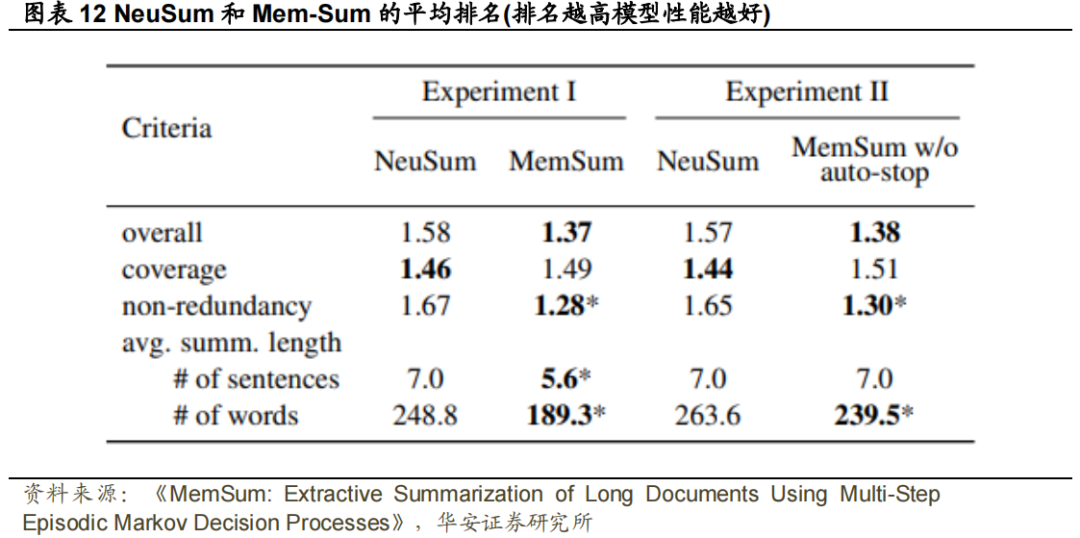
利用具有历史意识的多步情景马尔可夫决策过程可以有效地实现提取摘要。使用局部句子、全局上下文和提取历史的编码器,MemSum可以获得人类在总结文档时直观使用的信息。对提取历史的了解有助于MemSum生成紧凑的摘要,有效降低文档中的冗余。作为一个轻量级模型,MemSum在各种长文档摘要任务上都优于提取式方法的baseline和生成式方法的baseline。由于MemSum在这些任务上实现了SOTA性能,MDP方法在今后研究中可以作为一个优秀的模型设计选择。
文献来源:
核心内容摘选自Nianlong Gu,Elliott Ash和Richard H.R. Hahnloser 2022-05-22 在《Association for Computational Linguistics》上发表的文章《MemSum: Extractive Summarization of Long Documents Using Multi-Step Episodic Markov Decision Processes》
文献结论基于历史数据与海外文献进行总结;不构成任何投资建议。
本文内容节选自华安证券研究所已发布证券研究报告:《MemSum:基于多步情景马尔可夫决策过程的长文档摘要提取——“学海拾珠”系列之一百六十四》(发布时间:20231101),具体分析内容请详见报告。若因对报告的摘编等产生歧义,应以报告发布当日的完整内容为准。分析师:严佳炜 || 执业证书号:S0010520070001,分析师:骆昱杉 || 执业证书号:S0010522110001。“金工严选”公众号记录华安证券研究所金融工程团队的研究成果,欢迎关注重要声明
适当性说明
《证券期货投资者适当性管理办法》于2017年7月1日起正式实施,通过本微信订阅号/本账号发布的观点和信息仅供华安证券的专业投资者参考,完整的投资观点应以华安证券研究所发布的完整报告为准。若您并非华安证券客户中的专业投资者,为控制投资风险,请取消订阅、接收或使用本订阅号/本账号中的任何信息。本订阅号/本账号难以设置访问权限,若给您造成不便,敬请谅解。我司不会因为关注、收到或阅读本订阅号/本账号推送内容而视相关人员为客户。市场有风险,投资需谨慎。
投资评级说明
以本报告发布之日起12个月内,证券(或行业指数)相对于沪深300指数的涨跌幅为标准,定义如下:
行业及公司评级体系
买入—未来6-12个月的投资收益率领先市场基准指数15%以上;增持—未来6-12个月的投资收益率领先市场基准指数5%至15%;中性—未来6-12个月的投资收益率与市场基准指数的变动幅度相差-5%至5%;减持—未来6-12个月的投资收益率落后市场基准指数5%至15%;卖出—未来6-12个月的投资收益率落后市场基准指数15%以上;无评级—因无法获取必要的资料,或者公司面临无法预见结果的重大不确定性事件,或者其他原因,致使无法给出明确的投资评级。市场基准指数为沪深300指数。
分析师承诺
本人具有中国证券业协会授予的证券投资咨询执业资格,以勤勉的职业态度、专业审慎的研究方法,使用合法合规的信息,独立、客观地出具本报告,本报告所采用的数据和信息均来自市场公开信息,本人对这些信息的准确性或完整性不做任何保证,也不保证所包含的信息和建议不会发生任何变更。报告中的信息和意见仅供参考。本人过去不曾与、现在不与、未来也将不会因本报告中的具体推荐意见或观点而直接或间接收任何形式的补偿,分析结论不受任何第三方的授意或影响,特此证明。
免责声明
华安证券股份有限公司经中国证券监督管理委员会批准,已具备证券投资咨询业务资格。本报告中的信息均来源于合规渠道,华安证券研究所力求准确、可靠,但对这些信息的准确性及完整性均不做任何保证,据此投资,责任自负。本报告不构成个人投资建议,也没有考虑到个别客户特殊的投资目标、财务状况或需要。客户应考虑本报告中的任何意见或建议是否符合其特定状况。华安证券及其所属关联机构可能会持有报告中提到的公司所发行的证券并进行交易,还可能为这些公司提供投资银行服务或其他服务。
本报告仅向特定客户传送,未经华安证券研究所书面授权,本研究报告的任何部分均不得以任何方式制作任何形式的拷贝、复印件或复制品,或再次分发给任何其他人,或以任何侵犯本公司版权的其他方式使用。如欲引用或转载本文内容,务必联络华安证券研究所并获得许可,并需注明出处为华安证券研究所,且不得对本文进行有悖原意的引用和删改。如未经本公司授权,私自转载或者转发本报告,所引起的一切后果及法律责任由私自转载或转发者承担。本公司并保留追究其法律责任的权利。
本篇文章来源于微信公众号: 金工严选